Chapter 2 — Data Gravity, Egress Economics, and the Sovereign Cost Trap
The promise of the early cloud era was deceptively simple: centralise your data, and agility will follow. A single cloud region, a single data lake, a single analytical platform — the economy of scale and the simplicity of management would make the enterprise more responsive, more analytical, and more competitive. This promise was not entirely false. For enterprises in the first decade of cloud adoption, the movement of data to a centralised cloud platform did deliver genuine benefits: access to elastic compute, managed infrastructure, and analytical tooling that would have been economically prohibitive to operate on premises. The architectural model that delivered those benefits was, however, always predicated on conditions that were present in the early cloud era but have since ceased to hold: data volumes that were manageable, regulatory requirements that were accommodating of centralisation, and a competitive landscape between cloud providers that was expected to drive down the costs of data movement over time.
The reality of 2026 is materially different. Data volumes have grown by orders of magnitude. Regulatory requirements have become fundamentally hostile to the centralisation of personal and regulated data across jurisdictional boundaries. And the cost of moving data between cloud environments, rather than declining with time, has remained stubbornly significant, embedded in the pricing models of the major cloud providers as a structural feature rather than a transitional artefact. The enterprise that built its analytical architecture on centralisation assumptions in 2015 or 2018 now finds itself operating an infrastructure that is increasingly misaligned with the economic, regulatory, and operational realities it must navigate.
The concept of data gravity is the most useful analytical lens for understanding this misalignment. It explains why the problem is structural rather than incidental, and why the solution requires architectural rethinking rather than operational optimisation.
2.1 Understanding Data Gravity in the Multi-Cloud Era
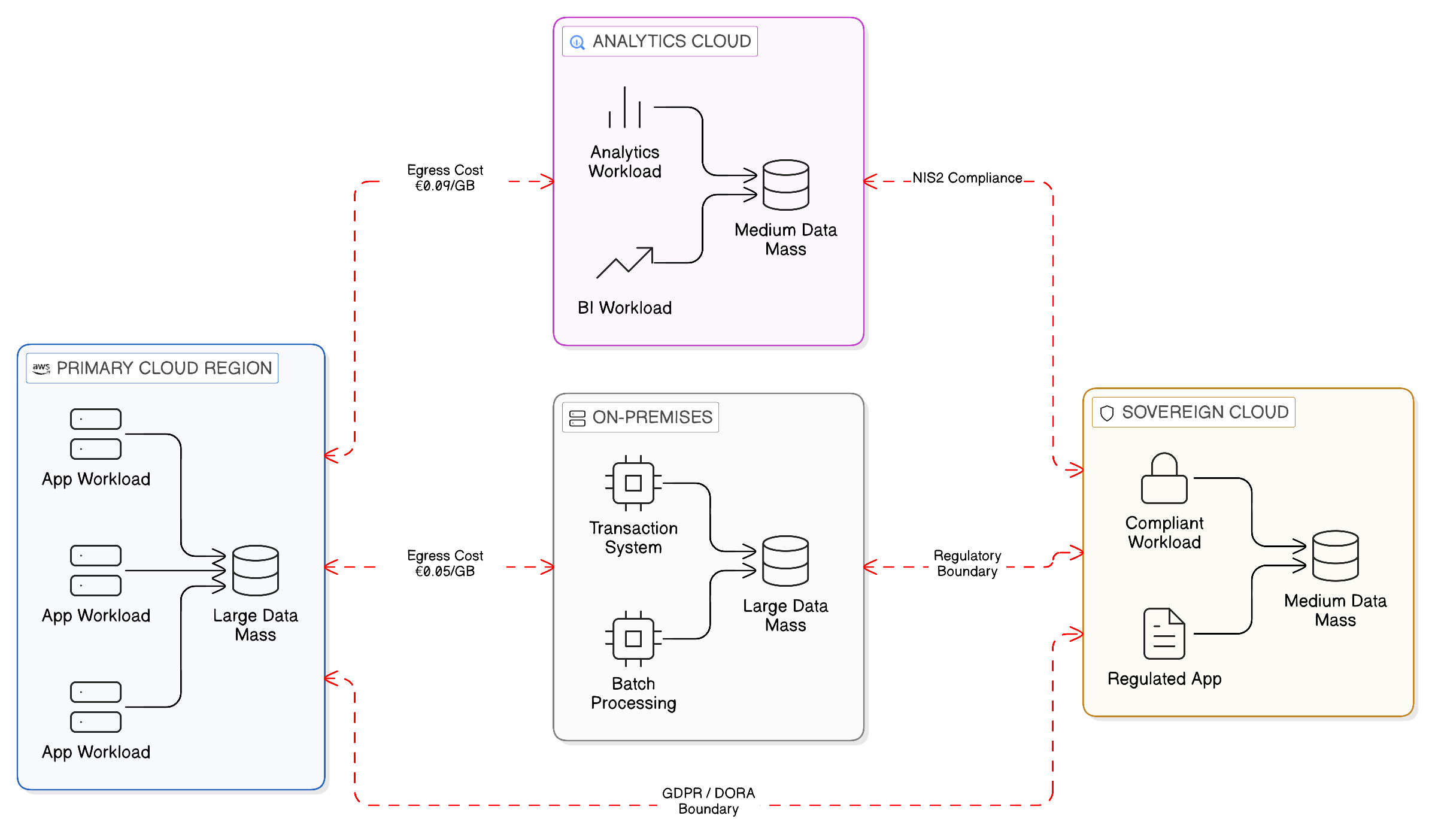
The concept of data gravity was introduced to describe the observation that data, like mass, exerts an attractive force on the applications, services, and processes that depend on it. A large dataset creates a gravitational well that pulls analytical workloads, machine learning pipelines, operational processes, and the engineering teams that build and maintain them towards the location at which the data resides. This attraction is not metaphorical; it is the practical consequence of the fact that moving data is expensive — in egress cost, in time, in latency, and in the engineering effort required to maintain the fidelity of the copy relative to the source — whilst moving computation to the data is, in an era of containerised, portable application runtimes, often much less expensive.
The gravitational metaphor is valuable because it captures two properties of the data-integration relationship that are often underappreciated. The first is that the attractive force grows with the size of the dataset. A small dataset — a configuration table, a reference lookup, a low-volume operational log — can be replicated cheaply and managed without significant governance effort. As the dataset grows in volume, in complexity, and in the number of systems that depend on it, the cost of replication increases, the governance burden of managing copies multiplies, and the operational risk of maintaining consistency between the source and its copies becomes progressively harder to manage. The second property is that data gravity is cumulative: multiple datasets located in proximity to each other create a compound gravitational well that makes it increasingly impractical to extract any single dataset for centralisation without also moving the ecosystem of related datasets that the application consuming it also requires.
In a single-cloud world, data gravity was primarily an architectural concern — the question of which services should be deployed in proximity to which datasets to minimise latency and avoid unnecessary inter-service data transfer. The answer was generally straightforward: co-locate analytical workloads with the data they process in the same cloud region, and the gravitational attraction could be satisfied without incurring significant egress costs. In the hybrid, sovereign, and multi-cloud world of 2026, data gravity has evolved into something considerably more complex: a structural constraint that simultaneously affects the economics, resilience, and regulatory compliance of the enterprise’s entire data infrastructure.
The multi-cloud enterprise does not have a single centre of gravity. It navigates multiple competing gravitational wells, each exerting its own attractive force and each creating its own cost and complexity when workloads or data must be moved between them. The primary cloud provider hosting the operational systems exerts one gravitational force. The secondary provider hosting the analytical platform exerts another. The on-premises data centre hosting the mainframe transaction system exerts a third, one that is particularly difficult to counteract because the technical cost of extracting data from mainframe environments is substantially higher than extraction from modern cloud-native data stores. And the sovereign cloud regions and edge environments that regulatory requirements or operational considerations are driving the enterprise to adopt exert additional forces, each pulling in directions that may be difficult to reconcile.
The traditional integration architecture’s response to this multi-polar gravitational landscape has been to attempt to overcome it through engineering effort: to build and maintain the replication pipelines that move data between gravitational wells, managing the latency, consistency, and cost of doing so as operational problems to be solved. This response was always inefficient; it has become increasingly untenable as the number of gravitational wells has grown and the regulatory constraints on moving data between them have tightened. The Zero-Copy response is architecturally more coherent: to accept the gravitational wells as given, and to design an integration architecture that works with them rather than against them, by moving computation to the data rather than data to the computation.
2.1.1 The Three Dimensions of Data Gravity Constraint
The constraint that data gravity imposes on enterprise integration architecture operates across three dimensions that interact with each other in ways that compound their individual effects. Understanding each dimension in isolation, and then understanding how they interact, is necessary for constructing the business case for Zero-Copy Integration that the board-level conversation requires.
The economic dimension is the most immediately legible. Egress fees — the charges that cloud providers levy on data leaving their infrastructure — are the most direct financial expression of data gravity. When data is large and the workloads that consume it are located in a different cloud environment, the cost of moving the data to the workload or maintaining a copy of the data near the workload is quantifiable and, increasingly, material. The economics of egress are examined in detail in Section 2.3; the point to establish here is that they are not a peripheral cost to be managed at the margins of the cloud budget. For data-intensive enterprises, they represent a structural cost that scales with business activity and that is, without architectural intervention, essentially uncapped.
The resilience dimension is less immediately visible but equally significant. An integration architecture that depends on the continuous replication of data between cloud environments inherits the failure modes of every network path, every replication process, and every schema dependency that the replication pipeline traverses. A network degradation between the source environment and the analytical environment does not merely slow the pipeline; it introduces an inconsistency between the source and the copy that may persist for hours or days if the pipeline does not have adequate error detection and recovery mechanisms. In an architecture with dozens of such dependencies, the probability that at least one is producing stale or inconsistent data at any given time is not negligible; it approaches statistical certainty. The operational consequence is that analytical and AI workloads that depend on replicated data cannot be fully trusted without continuous validation of the currency and completeness of the copies they consume.
The sovereignty dimension, which is examined in depth in Chapter 3, is the most structurally constraining. Data localisation requirements in an increasing number of jurisdictions prohibit or restrict the transfer of personal, financial, or regulated data across territorial boundaries, regardless of whether the source and destination are within the same cloud provider’s infrastructure. These requirements create a gravitational constraint of a different kind from the economic and resilience constraints: they are not a cost to be managed or a failure mode to be mitigated; they are a legal boundary that the integration architecture must respect as a structural property. An integration architecture that depends on the movement of regulated data across these boundaries is not merely expensive and fragile; it is non-compliant, and non-compliance with data sovereignty regulation in the EU, the United Kingdom, or the APAC jurisdictions that have adopted equivalent frameworks carries consequences that can include regulatory sanction, enforcement action, and reputational damage that dwarf the egress costs with which the economic analysis is concerned.
2.2 The Hidden Integration Tax
Senior technology leaders are, in general, well-informed about the direct costs of cloud infrastructure: compute, storage, and managed services are visible in cloud billing statements and are subject to the FinOps disciplines that most large enterprises have established. The integration tax — the total cost, complexity, and risk burden created by the movement of data across the enterprise’s integration estate — is far less visible, because it is distributed across multiple cost centres, partially absorbed into engineering team budgets as operational overhead, and partially externalised as regulatory and security risk that does not appear directly in financial statements until it crystallises as a breach, an enforcement action, or a compliance failure.
The integration tax has three constituent components, each of which is substantial on its own and all of which compound the effects of the others.
The financial component of the integration tax encompasses the direct egress costs described above, together with the storage costs of maintaining the replicated datasets at their destinations, the compute costs of the ETL and streaming processes that perform the replication, and the engineering labour costs of building, maintaining, and monitoring the replication infrastructure. This last component is particularly significant and particularly invisible to senior leadership: the engineering effort consumed by integration maintenance — debugging failed pipelines, resolving schema inconsistencies, managing the operational overhead of dozens of independently deployed replication processes — is rarely captured as a distinct cost category. It is absorbed into the operational budgets of platform and data engineering teams, where it crowds out the investment in higher-value architectural work that would reduce the integration tax over time. The integration tax is, in this sense, self-reinforcing: the more complex the integration estate, the more engineering capacity it consumes in maintenance, reducing the capacity available to simplify it.
The operational component of the integration tax is the cost of the fragility and inconsistency that the replication-centric architecture introduces. When a replication pipeline fails, the data it was maintaining falls out of currency: the analytical workloads and AI systems that consume the replicated data begin to operate on stale information, potentially producing incorrect conclusions or recommendations without any indication that the underlying data is no longer current. Detecting and diagnosing these failures requires monitoring infrastructure that must itself be built and maintained. Remediating them requires engineering intervention that is often time-critical if the staleness of the data is affecting operational decisions. The cumulative cost of these incidents — in engineering time, in operational disruption, and occasionally in the business consequences of decisions made on the basis of stale data — is significant and growing as the integration estate becomes more complex.
The risk component of the integration tax is the most difficult to quantify but potentially the most consequential. Every copy of sensitive data that is created as part of the replication architecture is a location at which that data could be exposed by a security breach, accessed without authorisation, or found to be in violation of data sovereignty requirements. The cost of a data breach is well-documented — IBM’s own Cost of a Data Breach research consistently places the average cost of a significant breach at multiple millions of dollars, with regulated industries such as healthcare and financial services experiencing materially higher costs. The cost of a data sovereignty enforcement action is less predictable but potentially larger: GDPR fines of up to four per cent of global annual turnover, combined with the operational disruption of a regulatory investigation and the reputational consequences of public enforcement action, create a risk exposure that is difficult to fully provision for in operational budgets but that is directly attributable to the replication architecture that created the unnecessary data copies.
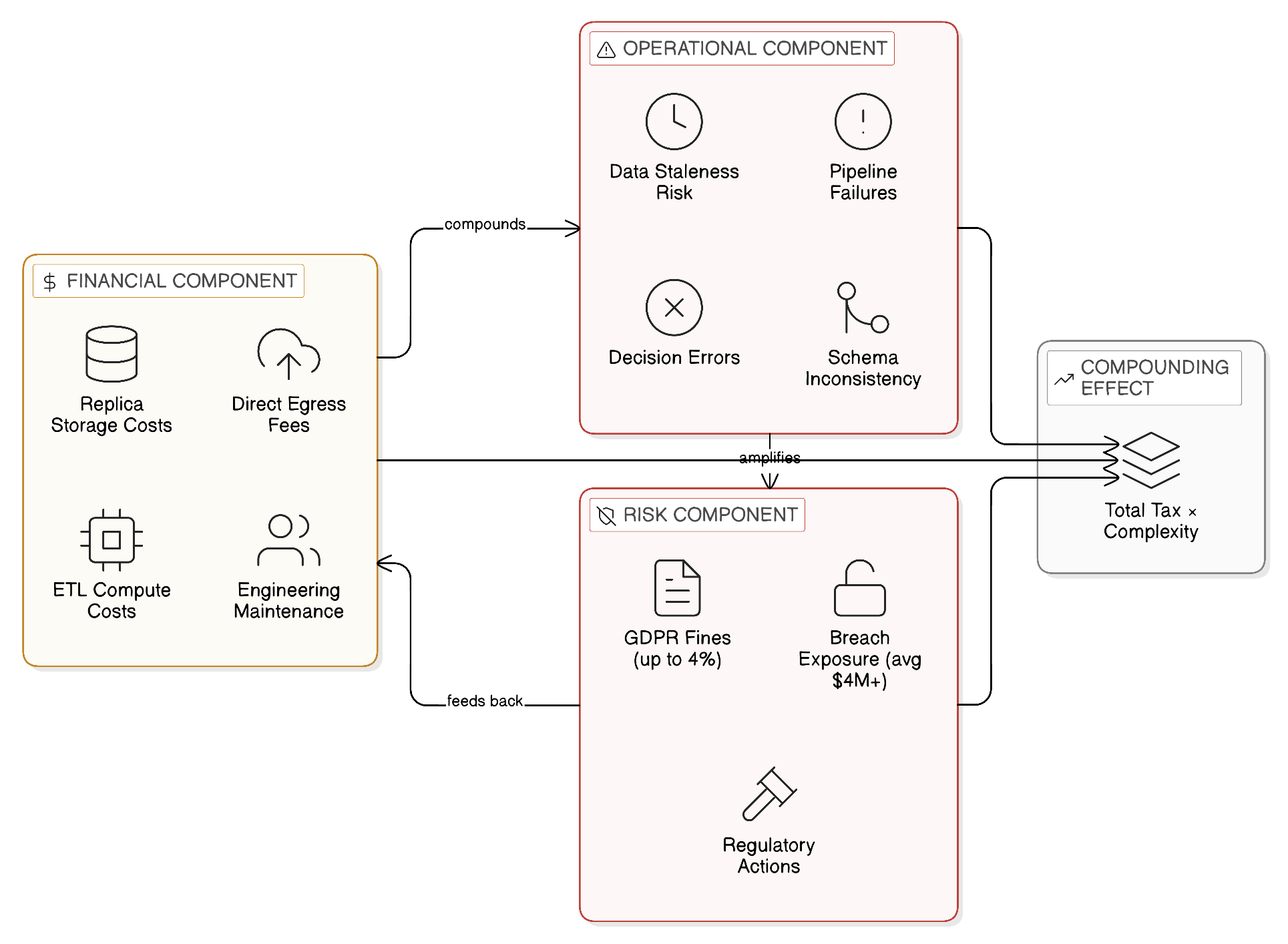 The primary contributors to the integration tax accumulation are patterns of data movement that each appear individually justified but that collectively create the conditions for the tax’s compounding growth. Nightly batch synchronisations — the legacy ETL process that moved data between systems in the era before real-time streaming was economically viable — persist in most large enterprises as a significant component of the integration estate, often unmaintained by their original authors and resistant to modernisation because the business processes they support have become dependencies on their specific timing and format characteristics. Point-to-point SaaS connectors, implemented by individual project teams without regard for the broader integration architecture, create a proliferation of data copies in SaaS-provider environments that are outside the enterprise’s direct governance control. And ad-hoc data exports — the spreadsheet extracts, the analyst-initiated database queries, the one-time ETL jobs that became permanent — accumulate in the corners of the data estate where governance visibility does not reach.
The primary contributors to the integration tax accumulation are patterns of data movement that each appear individually justified but that collectively create the conditions for the tax’s compounding growth. Nightly batch synchronisations — the legacy ETL process that moved data between systems in the era before real-time streaming was economically viable — persist in most large enterprises as a significant component of the integration estate, often unmaintained by their original authors and resistant to modernisation because the business processes they support have become dependencies on their specific timing and format characteristics. Point-to-point SaaS connectors, implemented by individual project teams without regard for the broader integration architecture, create a proliferation of data copies in SaaS-provider environments that are outside the enterprise’s direct governance control. And ad-hoc data exports — the spreadsheet extracts, the analyst-initiated database queries, the one-time ETL jobs that became permanent — accumulate in the corners of the data estate where governance visibility does not reach.
2.3 Modelling Egress Economics for the Board
The business case for Zero-Copy Integration at board level requires the translation of technical architecture concerns into financial terms that the board’s non-technical members can evaluate alongside the competing investments for capital allocation. This translation is the responsibility of the technology leader making the case, and it requires a level of analytical rigour that the technology function does not always apply to its investment proposals. The following framework provides the structure for that rigorous analysis.
The starting point for egress cost modelling is the construction of what might be termed the Data Movement Inventory: a systematic catalogue of the significant data flows in the enterprise’s integration estate, with each flow characterised by the volume of data it moves in a defined period, the source and destination of the flow, the cloud environments in which each endpoint resides, and the frequency and trigger of the movement. Most large enterprises do not have this inventory in a readily accessible form; constructing it requires analysis of cloud billing data, network traffic monitoring, integration platform logs, and in many cases manual investigation of individual systems and teams. The effort of constructing the inventory is itself informative: the discovery that hundreds of undocumented data flows exist, moving data between environments that the integration architecture team was not aware of, is a common outcome of this exercise and is itself a powerful illustration of the governance problem that the Zero-Copy architecture is designed to address.
With the Data Movement Inventory established, the financial modelling of egress exposure can be conducted with reasonable precision. The egress cost of each flow is the product of the volume of data moved per period, the egress rate applicable to the source environment, and the frequency of the movement. The sum of the egress costs of all flows in the inventory is the baseline egress cost of the current integration estate — the floor below which the integration tax cannot be reduced without architectural change. For most large enterprises that have conducted this analysis, the baseline figure is substantially larger than the cloud billing teams had estimated, because egress costs are distributed across multiple billing accounts, allocated to multiple cost centres, and frequently not analysed in aggregate.
The analytical framework can be extended to model the egress cost trajectory under different growth assumptions. Data volumes in the enterprise’s operational systems are growing, driven by increased transaction activity, more detailed event logging, expanded sensor and telemetry data from operational assets, and the higher fidelity data that AI and advanced analytics workloads require. If the integration architecture remains unchanged, the egress costs of the current replication flows will grow in proportion to the growth of the underlying data volumes. This trajectory can be modelled with reasonable confidence using historical data volume growth rates and the egress pricing of the current cloud environment, and the resulting forward projection provides the second component of the business case: the cost of inaction, expressed as the net present value of the egress costs that the enterprise will incur over a five-year horizon if the integration architecture is not reformed.
The concept of data gravity can be given a more precise analytical expression for the purposes of this modelling. The gravitational force that a dataset exerts on the workloads that depend on it — the force that makes it expensive and operationally disruptive to move the data rather than the workloads — can be approximated as a function of the dataset’s mass (its volume), its proximity to dependent workloads (measured in terms of network latency and egress cost per unit volume), and the jurisdictional and technical boundaries that any movement must cross:
Gravity = (Mass × Dependency Density) / (Movement Cost × Jurisdictional Friction)
In this formulation, datasets with high mass, high dependency density (many workloads depending on the dataset), high per-unit movement cost, and high jurisdictional friction (regulatory constraints on movement) exert the greatest gravitational force and represent the strongest candidates for Zero-Copy treatment. Datasets that are small, have few dependents, are cheap to move, and face no regulatory restrictions on movement may legitimately be candidates for replication, particularly where the latency or availability requirements of their consuming workloads cannot be satisfied by federated access mechanisms.
This analytical framework provides the prioritisation tool that technology leaders need to sequence the Zero-Copy transformation: by calculating the gravitational force of each significant dataset in the inventory, the architecture team can identify the flows where Zero-Copy treatment will deliver the greatest reduction in egress cost, operational fragility, and regulatory risk, and sequence the transformation to address those flows first.
2.3.1 A Worked Example: The RegDataBank Portfolio
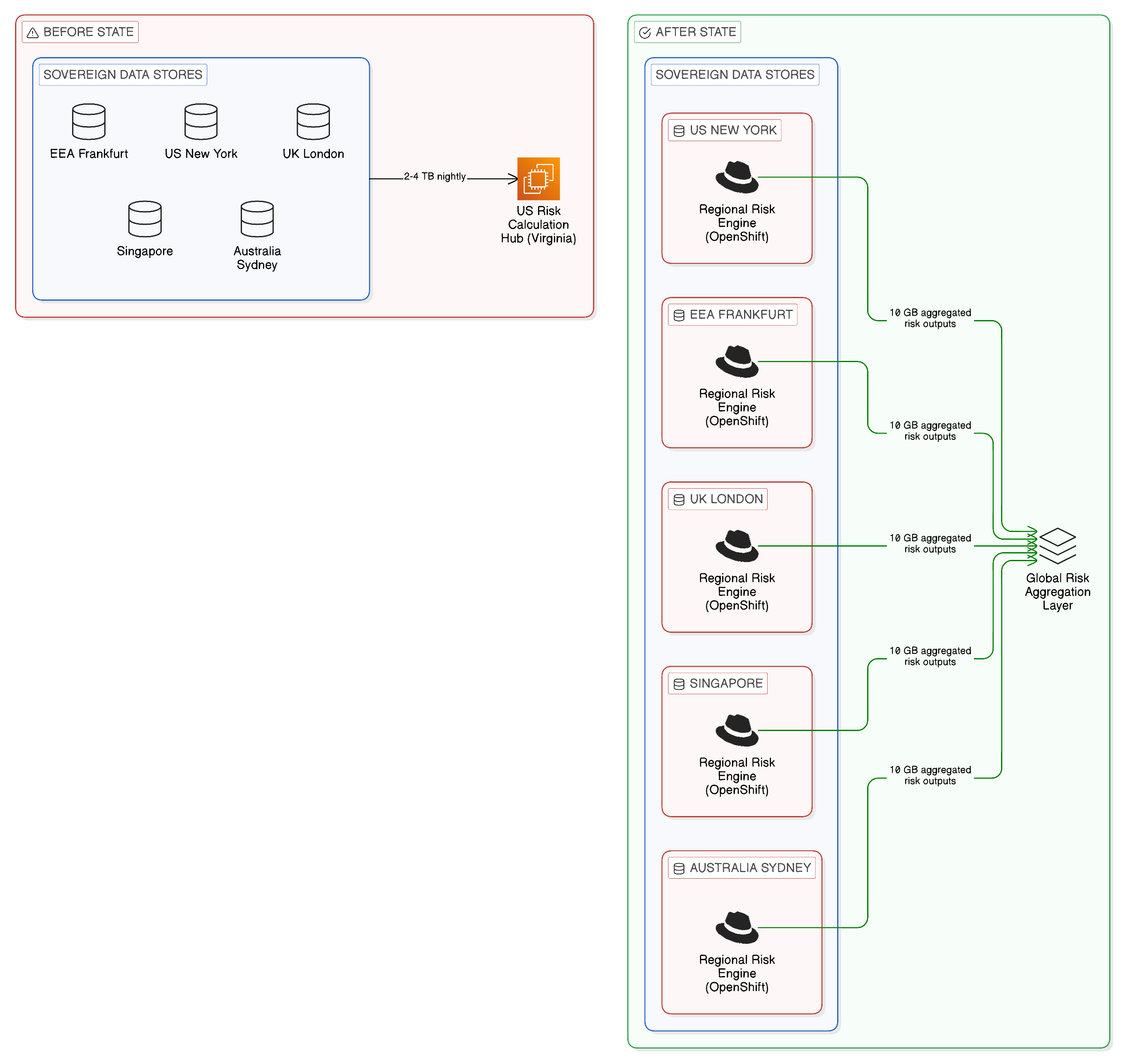
RegDataBank, a composite drawn from engagements with several major global financial institutions, provides a concrete illustration of how the egress economics framework applies in practice. RegDataBank operates across five regulatory jurisdictions: the European Economic Area, the United Kingdom, the United States, Singapore, and Australia. Its core trade and position data is held in sovereign data stores within each jurisdiction, as required by the prudential regulators in each territory. Its risk management and reporting function, however, was historically consolidated in a single US cloud region, where the risk modelling infrastructure had been built over the preceding decade.
To produce the daily risk reports required by its regulators in each jurisdiction, RegDataBank’s architecture required the export of position data from each of the five sovereign data stores to the US cloud region, where the risk models were executed and the consolidated reports produced. The volumes involved were substantial: each nightly export transferred between two and four terabytes of position and market data from each jurisdiction, for a total nightly transfer of ten to twenty terabytes across the five jurisdictions. At standard inter-regional egress rates, the direct cost of these exports was in the region of $15,000 to $25,000 per day, or $5.5m to $9m annually, before accounting for the storage costs of the transferred data at the US destination or the engineering costs of the extraction and loading processes.
The regulatory risk was equivalent in materiality to the financial cost. RegDataBank’s EEA operations were subject to DORA’s operational resilience requirements, which raised questions about whether the concentration of critical risk calculation in a single non-EEA cloud region constituted an acceptable concentration risk from the perspective of the European prudential regulator. The regulators in Singapore and Australia had separately queried whether the transfer of position data to a US environment was consistent with the financial data localisation requirements of their respective jurisdictions. And the UK’s Prudential Regulation Authority had included the cross-border data transfer arrangement in its operational resilience assessment of RegDataBank’s UK operations, noting the dependency on US infrastructure as a potential single point of failure.
The Zero-Copy transformation that RegDataBank implemented addressed the financial cost and the regulatory risk simultaneously, because the two were symptoms of the same architectural problem. Regional risk calculation capabilities were deployed within each jurisdiction, using containerised runtime environments on Red Hat OpenShift clusters operated in the jurisdictionally appropriate cloud or on-premises infrastructure. The risk models were distributed to these regional environments, with the IBM Cloud Satellite management plane maintaining consistency of model versions across jurisdictions without requiring the underlying position data to leave the jurisdiction in which it was held. Global consolidated risk reports were produced by a federated aggregation process that collected only the summarised risk outputs — position aggregates, exposure totals, VaR figures — from each regional calculation environment, rather than the detailed position data from which those outputs were derived.
The financial impact of the transformation was measurable with precision: nightly cross-jurisdictional data transfer volumes fell from ten-to-twenty terabytes to less than fifty gigabytes of aggregated outputs, a reduction of more than 99 per cent. The direct egress cost reduction was proportionate. The regulatory risk was resolved rather than merely mitigated: with risk calculation executing within each jurisdiction on locally-held data, the concentration risk and data localisation concerns that regulators had raised were addressed at an architectural level, not merely managed through contractual or governance arrangements.
2.4 The Sovereign Cost Trap
The Sovereign Cost Trap is a specific manifestation of the data gravity problem that deserves distinct analytical treatment, because it represents a condition in which the enterprise is simultaneously incurring the costs of complying with sovereignty requirements and the costs of a centralised integration architecture that those sovereignty requirements are incompatible with. The result is an enterprise that pays twice: once for the compliance measures required to make centralisation legally defensible, and again for the operational and financial costs of the centralised architecture that sovereignty regulation is progressively rendering unsustainable.
The trap arises when an organisation’s strategic response to data sovereignty requirements is to implement minimum-viable compliance measures on an existing centralised architecture rather than to re-examine the architecture in light of the sovereignty requirements. The minimum-viable compliance measures — Standard Contractual Clauses, data transfer impact assessments, additional encryption and access controls on the transferred data, contractual commitments from cloud providers regarding data handling — add cost and complexity to the existing architecture without resolving its fundamental incompatibility with the sovereignty requirements they are intended to address. They create a compliance posture that is legally fragile: dependent on the continued validity of the contractual and regulatory frameworks that underpin them, and vulnerable to invalidation by judicial decisions, regulatory reinterpretation, or changes in the political environment that governs cross-border data transfer.
The enterprise in the Sovereign Cost Trap has, in effect, constructed an architecture on a foundation that is being progressively eroded. Each new regulatory development — a new data localisation requirement, a new adequacy decision invalidation, a new operational resilience standard that questions the concentration of critical processing outside the regulated jurisdiction — requires an additional layer of compliance measures to be applied to the existing architecture, each adding cost and complexity without addressing the underlying structural incompatibility. The enterprise continues to pay the integration tax of the centralised architecture whilst simultaneously investing in compliance measures that delay but do not prevent the eventual architectural reckoning.
The RegDataBank example above illustrates how an organisation that has recognised its position in the Sovereign Cost Trap can escape it through architectural transformation rather than additional compliance investment. The key insight that drives the transformation is that the most effective response to sovereignty requirements is not to negotiate terms on which regulated data can cross borders, but to redesign the architecture so that it does not need to.
2.4.1 Recognising the Trap in Practice
The Sovereign Cost Trap manifests in recognisable patterns that technology leaders can use to assess whether their enterprise is caught within it. The first pattern is escalating compliance cost: the enterprise’s legal and compliance function is consuming increasing resources in the assessment, documentation, and maintenance of the legal bases for cross-border data transfers, and those resources are growing year-on-year as the regulatory environment becomes more demanding. This escalation is not attributable to the growth of the business but to the increasing scrutiny that regulators apply to cross-border transfer arrangements that were established under less demanding frameworks.
The second pattern is regulatory interrogation: the enterprise is receiving questions from regulators, data protection authorities, or prudential supervisors about specific data transfer arrangements, and the responses to those questions require significant legal and technical effort to prepare. The questions themselves are a signal that the regulator is not satisfied with the adequacy of the existing compliance arrangements; their escalation over successive regulatory cycles is a signal that the existing arrangements are under increasing pressure.
The third pattern is fragile legal basis: the enterprise’s ability to make cross-border data transfers depends on legal frameworks — adequacy decisions, Standard Contractual Clauses, Binding Corporate Rules — that are subject to legal challenge or regulatory reinterpretation. The Schrems II decision, which invalidated the EU-US Privacy Shield framework, is the most prominent example of a legal basis being removed without notice; it is not the last. An enterprise whose cross-border transfer arrangements depend on legal frameworks that could be invalidated by judicial or regulatory action is in a structurally fragile position that architectural redesign, rather than additional legal work, is the appropriate remedy for.
2.5 Zero-Copy Patterns to Escape Gravity: An Architectural Framework
The four patterns through which enterprises escape the data gravity well and the Sovereign Cost Trap are not independent techniques to be selected from a menu; they are complementary architectural capabilities that together constitute the Zero-Copy Integration model. In mature implementations, all four are present in the integration estate, applied to different categories of integration requirement based on the characteristics of the data, the access patterns of the consuming workloads, and the governance requirements of the relevant regulatory framework.
2.5.1 In-Place Analytics and Federated Query
The first and most foundational pattern is the elimination of analytical replication through the deployment of federated query capabilities that execute analytical workloads in the environment where the data resides, returning results rather than raw data to the analytical consumer. This is the pattern that most directly addresses the data gravity problem: by moving the computation to the data, it eliminates the egress cost of moving the data to the computation, without compromising the analytical capability of the workload.
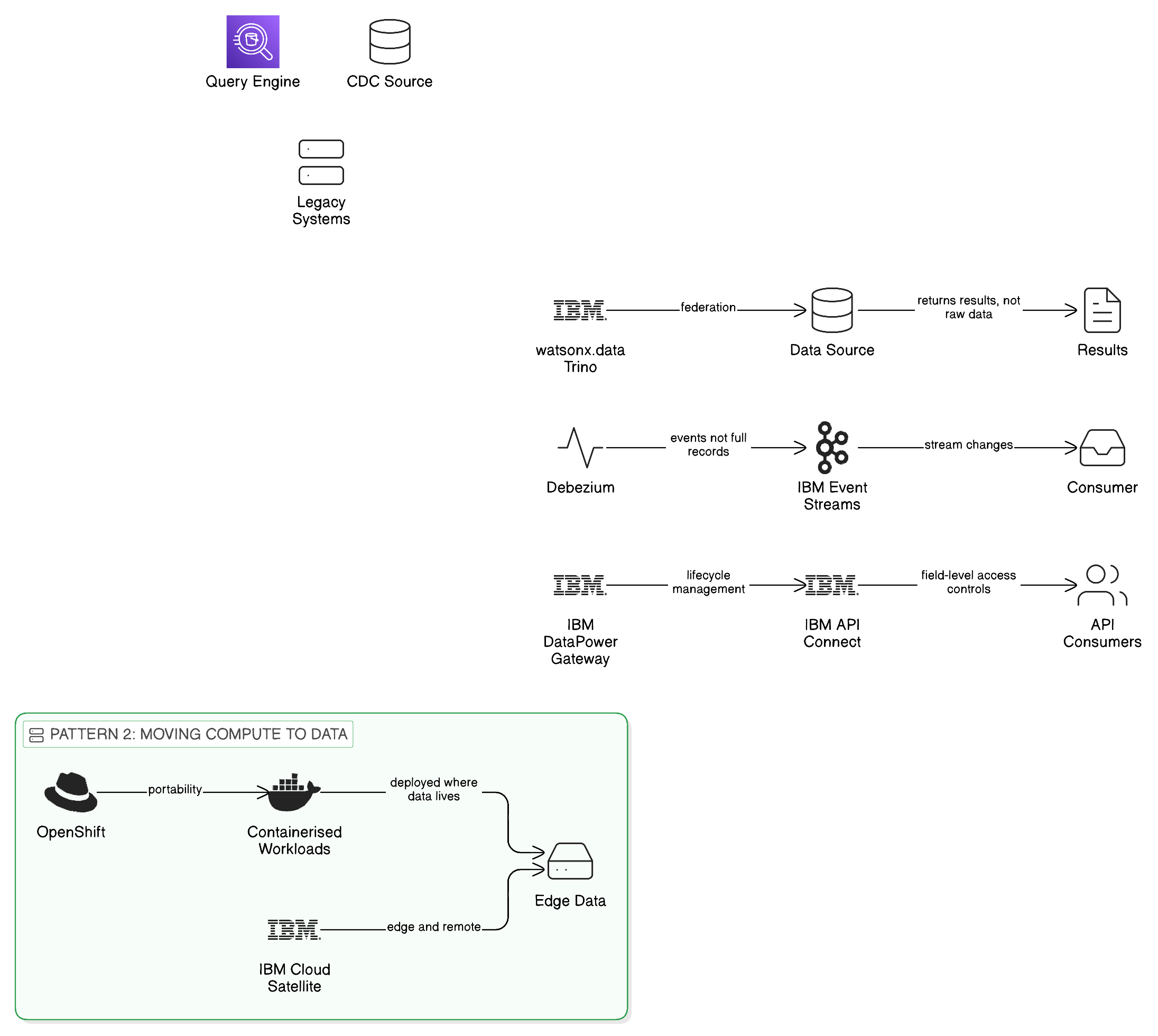
The technical infrastructure for federated query in a Zero-Copy architecture is examined in depth in Chapter 5. At the conceptual level, the pattern involves a query orchestration layer that accepts analytical queries expressed in a standard language — typically SQL, in the enterprise analytics context — and distributes the execution of those queries to the data environments in which the relevant datasets reside. Each environment executes the portion of the query relevant to its locally-held data and returns the results to the orchestration layer, which combines them and presents a unified result to the analytical consumer. The data does not move; only the query and the result traverse the federation layer.
IBM watsonx.data, built on the open-source Presto and Trino query federation engines and extended with IBM’s enterprise governance integration, provides the managed implementation of this pattern. Its significance for the data gravity problem is that it provides the query orchestration capability without requiring modification of the underlying data stores: the data remains in whatever format and system it currently occupies, and the federation layer presents it through a unified query interface. This means that the transition from a replication-based analytical architecture to a federated one does not require the migration of underlying data stores; it requires the deployment of the federation layer and the reconfiguration of analytical workloads to submit queries to the federation layer rather than to their own local copies of the data.
2.5.2 Moving Compute to Data
The second pattern addresses the operational workloads — application services, processing pipelines, AI inference endpoints — that currently depend on data being co-located with them in a specific cloud environment. Rather than moving the data to the computation, these workloads are themselves deployed in the environment where the data resides, eliminating the need for cross-environment data transfer. This is not a trivial transformation for workloads that are tightly coupled to a specific cloud environment; it requires that the application runtime be portable, deployable consistently across different environments without modification, and manageable from a central operational plane that does not require the workload to be in any specific location.
Red Hat OpenShift, IBM’s enterprise Kubernetes platform, provides the application runtime portability that this pattern requires. A workload containerised and deployed on OpenShift can be run on any cloud provider’s infrastructure, in an on-premises data centre, or at an edge location, with a consistent operational experience managed through OpenShift’s unified control plane. IBM Cloud Satellite extends this capability to remote and disconnected environments, enabling OpenShift clusters to be deployed in locations where connectivity to the central management plane is intermittent, maintaining operational consistency even when the cluster is operating in a partially disconnected state.
The architectural consequence of this pattern for data gravity is significant: it inverts the relationship between data and workload that the traditional cloud migration model assumed. Rather than migrating data to the cloud environment that hosts the workload, the enterprise deploys the workload in the environment that hosts the data. The gravitational well remains, but it is no longer a problem; the workload has been moved into it, rather than the data being extracted from it.
2.5.3 Event-Driven Integration in Place of Bulk Replication
The third pattern addresses the integration use case that has historically been most dependent on bulk data replication: the propagation of changes in one system’s data to the dependent systems that need to reflect those changes. In the copy-first model, this is typically implemented by periodically extracting the changed records from the source system — or, in the most unsophisticated implementations, extracting the entire dataset — and loading them into the dependent systems. This approach is expensive in egress terms because it moves the full volume of changed data, and it is operationally fragile because it depends on the batch pipeline running successfully on its defined schedule.
The Zero-Copy alternative is Change Data Capture (CDC) and event-driven integration: the source system publishes an event describing each change as it occurs, and dependent systems consume those events and update their own state accordingly. The key architectural difference from bulk replication is that the event describes the change, not the changed record itself. An event that says “customer record 12345 was updated, specifically the email address field changed from X to Y” is orders of magnitude smaller than a replication of the entire customer record, and it is available immediately rather than at the next scheduled batch execution. The dependent system receives the information it needs to update its own state — specifically that field of that record changed in that way — without receiving a copy of the record itself.
IBM Event Streams, IBM’s managed distribution of Apache Kafka, and IBM MQ for reliable messaging provide the enterprise event streaming and message queuing infrastructure for this pattern. Debezium, the open-source CDC framework, provides the capture capability that extracts change events from source databases without requiring modification to the source application, publishing them to the event stream. The combination of Debezium-based capture with IBM Event Streams-based distribution and IBM MQ-based delivery provides a complete, enterprise-grade event-driven integration capability that can replace bulk replication flows for the majority of operational integration use cases, with a fraction of the egress cost and materially better real-time consistency.
2.5.4 Zero-Copy API Façades for Legacy Systems
The fourth pattern addresses the specific challenge of legacy systems — mainframe applications, packaged ERP platforms, first-generation operational databases — that hold significant regulated data but do not support the modern API interfaces through which Zero-Copy access would naturally be implemented. These systems cannot be queried by a federation engine without a translation layer; their data cannot be captured by CDC tooling without specific integration work; and their internal data structures are often poorly documented and resistant to modification.
The Zero-Copy API façade interposes a thin governance and translation layer between the legacy system and its consuming applications. The façade presents a modern, versioned API interface to consumers, translating API requests into the native query or messaging protocols of the legacy system and returning results as governed API responses. The legacy system’s data does not move; the façade provides the governed access interface through which it can be accessed in place. Field-level access controls are enforced at the façade, ensuring that consumers receive only the data they are authorised to access, regardless of the legacy system’s own access control capabilities. And the façade records every data access in the lineage system, providing the audit trail that the governance framework requires.
IBM API Connect provides the management and lifecycle plane for the API façade, including the developer portal through which consuming applications discover and subscribe to the APIs it exposes. IBM DataPower Gateway provides the runtime enforcement of security policy, rate limiting, and content filtering for APIs that expose particularly sensitive legacy data. IBM App Connect provides the integration adapter framework through which the façade connects to specific legacy systems, with pre-built adapters for IBM Z mainframe systems, SAP and Oracle ERP platforms, and IBM Db2 database environments that accelerate the implementation of façades for the most common legacy integration targets.
2.6 Quantifying the Business Case: The Integration Economics Model
The preceding sections have established the qualitative case for Zero-Copy Integration in terms of egress economics, data gravity, and the Sovereign Cost Trap. For the board-level investment case, the qualitative argument must be supported by a quantitative model that makes the financial benefits of architectural transformation specific, defensible, and comparable to the investment required to achieve them. This section describes the structure of that model.
The model has four components: the baseline integration cost, the risk-adjusted cost of the current integration estate, the projected benefit of Zero-Copy transformation, and the cost and timeline of the transformation programme. Each component requires data that is specific to the enterprise’s own integration estate; generic industry benchmarks can provide a sense of scale but cannot substitute for the analysis of actual data flows, actual egress charges, and actual compliance costs.
The baseline integration cost encompasses the direct financial costs of the current integration estate: the egress charges as identified by the Data Movement Inventory, the storage costs of replicated datasets, the compute costs of ETL and streaming replication processes, and the engineering labour costs of maintaining the replication infrastructure. For most large enterprises, this baseline figure, when assembled for the first time across all cost centres and cloud billing accounts, is substantially higher than any previous estimate, because the costs are distributed across many accounts and rarely analysed in aggregate.
The risk-adjusted cost of the current architecture adds the expected value of the risk exposures that the replication architecture creates. This includes the expected cost of security incidents attributable to unnecessary data copies, modelled using IBM’s Cost of a Data Breach research or equivalent actuarial data; the expected cost of regulatory enforcement actions attributable to cross-border data transfer non-compliance, modelled using the enterprise’s regulatory risk assessment; and the expected operational cost of integration failures and data inconsistency incidents, modelled using historical incident data from the integration estate. These risk costs are genuinely uncertain, but the expected value calculation — probability of occurrence multiplied by cost of occurrence — provides a financially coherent representation of the risk exposure that the board can compare with the investment required to reduce it.
The projected benefit of Zero-Copy transformation is the reduction in baseline integration cost and risk-adjusted cost that the transformation programme is expected to achieve. Experience with Zero-Copy transformation programmes across multiple enterprises and industries suggests that well-executed programmes typically achieve egress cost reductions of 60 to 80 per cent for the replication flows they address, with some programmes achieving reductions in excess of 90 per cent where the bulk of egress cost is attributable to a small number of high-volume replication flows. The engineering cost reduction from simplified integration architecture — fewer pipelines to maintain, more standard interfaces to operate — is typically in the range of 20 to 40 per cent of integration engineering labour once the transformation is substantially complete.
2.7 The CIO Dashboard for Data Sovereignty and Integration Economics
Effective management of an integration estate in transition from copy-first to Zero-Copy requires measurement infrastructure that makes the state of the transition visible to the technology leaders who are responsible for it, and that provides the evidence base for the continuing investment case. The following set of metrics and indicators constitutes the core of a management dashboard for the Zero-Copy transformation programme.
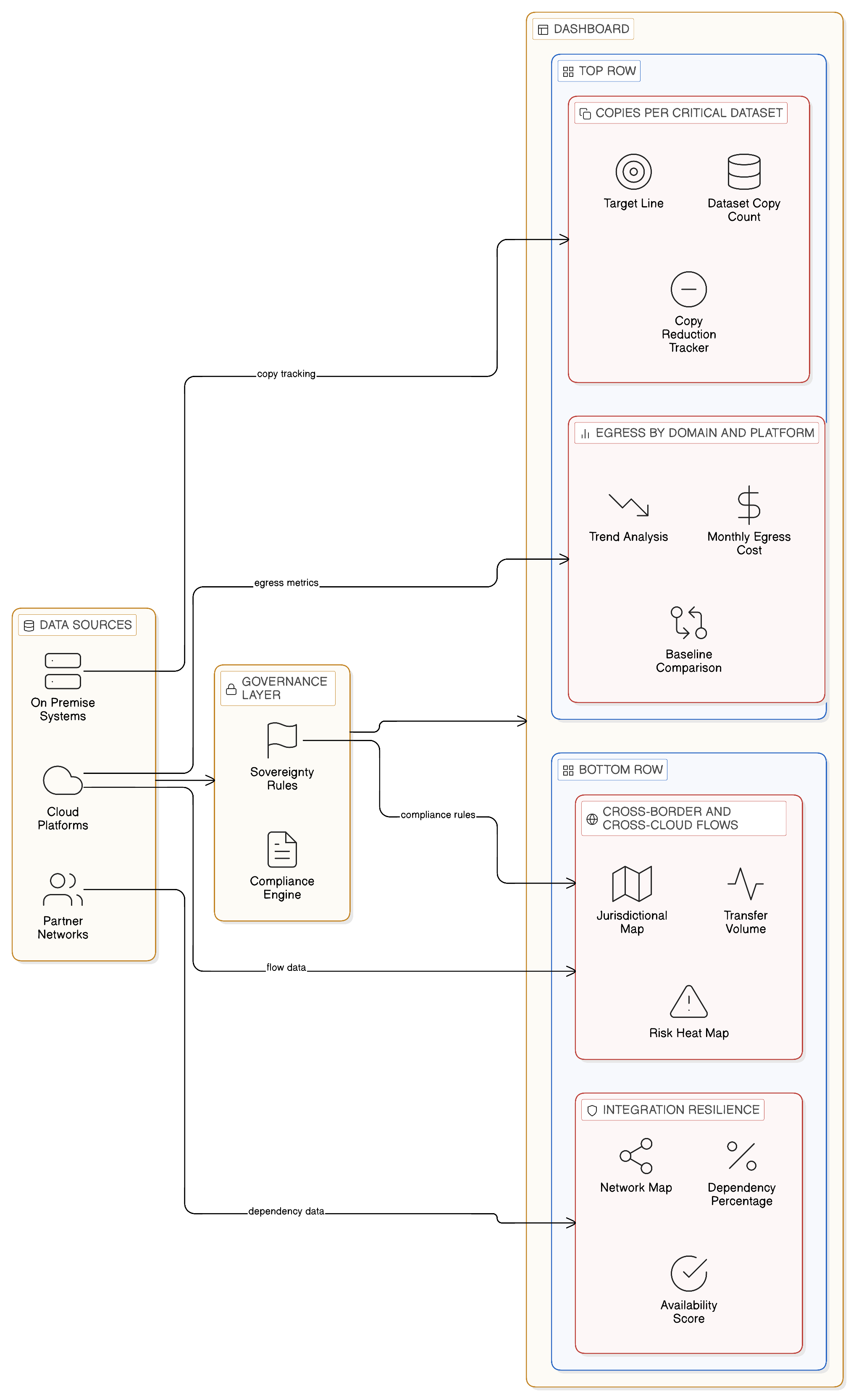 Egress by domain and platform is the foundational financial metric. By analysing cloud billing data at the level of the consuming business domain rather than merely at the level of the cloud account, the dashboard identifies which business units are driving the highest data movement costs and provides the basis for prioritising Zero-Copy treatment of the most expensive flows. This metric should be reported monthly, tracked against a baseline established at the start of the transformation programme, and presented alongside the egress cost trajectory that would apply if no transformation were undertaken, to maintain the visibility of the programme’s financial benefit.
Egress by domain and platform is the foundational financial metric. By analysing cloud billing data at the level of the consuming business domain rather than merely at the level of the cloud account, the dashboard identifies which business units are driving the highest data movement costs and provides the basis for prioritising Zero-Copy treatment of the most expensive flows. This metric should be reported monthly, tracked against a baseline established at the start of the transformation programme, and presented alongside the egress cost trajectory that would apply if no transformation were undertaken, to maintain the visibility of the programme’s financial benefit.
Copies per critical dataset is the governance metric that tracks the enterprise’s progress in reducing the unnecessary proliferation of sensitive data. For each dataset classified as sensitive or regulated in the governance catalogue, this metric counts the number of physical copies that exist in the enterprise’s data estate, across all cloud environments, on-premises systems, and analytical platforms. The target is not zero copies — some controlled replication is architecturally justified — but a demonstrably managed and declining count of uncontrolled copies. IBM Knowledge Catalog’s automated discovery capabilities can provide the technical foundation for this metric, identifying copies of catalogued datasets across the estate and associating each copy with a governance record that documents its justification and lifecycle.
Cross-border and cross-cloud flows tracks the number and volume of data transfers that cross jurisdictional or cloud-provider boundaries. This metric provides the compliance function with the visibility it needs to assess the enterprise’s cross-border transfer risk and to prioritise the legal and architectural work required to address the highest-risk flows. It also provides the input to the regulatory reporting that some frameworks, including DORA’s register of information and outsourcing arrangements, require enterprises to maintain about their significant cross-border data dependencies.
Integration resilience, expressed as the percentage of critical business processes that are dependent on data from environments with which connectivity is currently degraded or unavailable, provides the operational risk perspective. This metric is most valuable when calculated dynamically, using real-time network monitoring and dependency mapping, so that the impact of an active connectivity degradation is visible in real time rather than discovered only when a downstream business process fails.
2.8 Summary and Architectural Imperatives
This chapter has examined the economics of data gravity and the Sovereign Cost Trap in depth, establishing the quantitative framework for the Zero-Copy business case and describing the four integration patterns through which the enterprise escapes the gravitational well of its current architecture. The analysis demonstrates that the costs of the copy-first integration model are not merely operational inconveniences; they are structural liabilities that grow with the scale and regulatory complexity of the enterprise’s data estate and that are, without architectural intervention, self-reinforcing.
For the technology leader translating this analysis into organisational action, several imperatives emerge. The most urgent is to establish the Data Movement Inventory: the systematic catalogue of significant data flows across the integration estate that provides the foundation for both the business case and the prioritisation of transformation effort. Without this inventory, the true scale of the integration tax is invisible, the business case for transformation cannot be constructed with the analytical rigour that board approval requires, and the highest-priority opportunities for Zero-Copy transformation cannot be identified with confidence.
The second imperative is to construct the integration economics model with data specific to the enterprise’s own estate. Generic industry benchmarks provide a context for the analysis but cannot substitute for the enterprise-specific cost and risk data that makes the business case compelling and defensible. The investment of analytical effort in constructing a rigorous, evidence-based model is itself a demonstration of the governance maturity that the Zero-Copy architecture requires.
The third imperative is to establish the management dashboard before the transformation programme begins, not after. Measurement of the programme’s financial and governance benefits requires a baseline against which progress can be measured, and the metrics that demonstrate progress require data collection infrastructure that must be in place from the start of the programme to be available at the stages where the business case for continued investment must be renewed.
The following chapter examines the regulatory and sovereignty landscape that shapes the architectural requirements of the Zero-Copy enterprise in greater depth, providing the compliance framework within which the integration economics analysis must be situated.
If you are finding this content useful, please consider supporting the author's efforts by purchasing a complete digital or hard-copy version.
Zero-Copy Integration: Architecture for the Fragmented Enterprise
© 2026 by Alan Hamilton
is licensed under CC BY-SA 4.0
![]()
![]()
![]()