Chapter 8 — Security-by-Design for Zero-Copy Architectures
Attack Surface, Policy Enforcement, Confidential Computing, and the Security Posture of the Data-Minimised Enterprise
The preceding chapters of this part have examined the three functional planes of the Zero-Copy Integration architecture: the Data Plane, which provides governed, in-place access to data assets without physical movement; the Application Integration Plane, which connects services through published, versioned API contracts mediated by policy-enforcing gateways; and the Event Plane, which propagates state changes as lightweight notifications rather than bulk data transfers. Each plane has been assessed primarily in terms of its integration capabilities and its contribution to the sovereignty and resilience objectives of the enterprise. This chapter examines a dimension that is present, implicitly, in every design decision described to this point: the security implications of the architectural choices the enterprise makes about how data is stored, accessed, and communicated.
The relationship between the Zero-Copy philosophy and enterprise security is not incidental but structural. Every copy of sensitive data that exists in the enterprise is a potential point of compromise: a location at which an attacker might gain unauthorised access, at which an inadvertent disclosure might occur, or at which the regulatory obligation to protect the data might be inadequately implemented. The proliferation of data copies that characterises the replication-centric integration model is therefore not merely an economic and governance problem, as earlier chapters have established; it is a security problem of the first order. The enterprise that maintains dozens of replicas of its customer data, its financial records, or its intellectual property across multiple cloud providers, data warehouses, and operational caches has created dozens of potential breach surfaces, each of which must be individually secured, monitored, and audited.
Zero-Copy Integration reduces this attack surface not as a side-effect of its primary objectives but as a direct architectural consequence of its foundational principle: data that is not moved cannot be breached in transit, cannot be found in an unintended location, and cannot be exposed through the compromise of a replica that need not have existed. This reduction in attack surface is, in the view of any thoughtful security architect, one of the most compelling arguments for adopting the Zero-Copy approach — and it is an argument that resonates equally with Chief Information Security Officers, data protection regulators, and the executive leadership whose organisations bear the consequences of significant data breaches.
This chapter examines the security architecture of the Zero-Copy enterprise in depth. It begins by establishing the precise nature and scale of the attack surface that replication creates, before articulating the security posture that Zero-Copy Integration enables. It then examines Zero Trust architecture as the overarching security model within which the Zero-Copy discipline operates. It addresses the specific security mechanisms that support and reinforce a Zero-Copy architecture: policy-as-code frameworks including Open Policy Agent and Kyverno; attribute-based access control as the governance model for fine-grained data access; IBM Guardium as the enterprise data security and compliance platform; IBM Hyper Protect as the confidential computing and workload protection capability; and the identity federation mechanisms that enforce consistent access governance across the multi-cloud enterprise. It addresses encryption across the full data lifecycle — in transit, at rest, and in use — before examining three secure access patterns that bring the mechanisms together. The chapter concludes by examining IBM QRadar and the Security Operations Centre integration that provides the threat detection and response capability the Zero-Copy security architecture ultimately requires.
8.1 The Attack Surface Created by Replicated Data
To appreciate the security advantages of the Zero-Copy approach, it is necessary to understand with some precision how data replication creates and amplifies security risk. The concept of attack surface — the sum of all the different points through which an attacker might enter a system or extract data from it — is a well-established framework in security architecture, but its application to enterprise data management is less consistently practised than its application to network security or application security. The result is that many enterprises manage their perimeter security with considerable sophistication whilst remaining largely unaware of the scale of the internal attack surface that their data management practices have created.
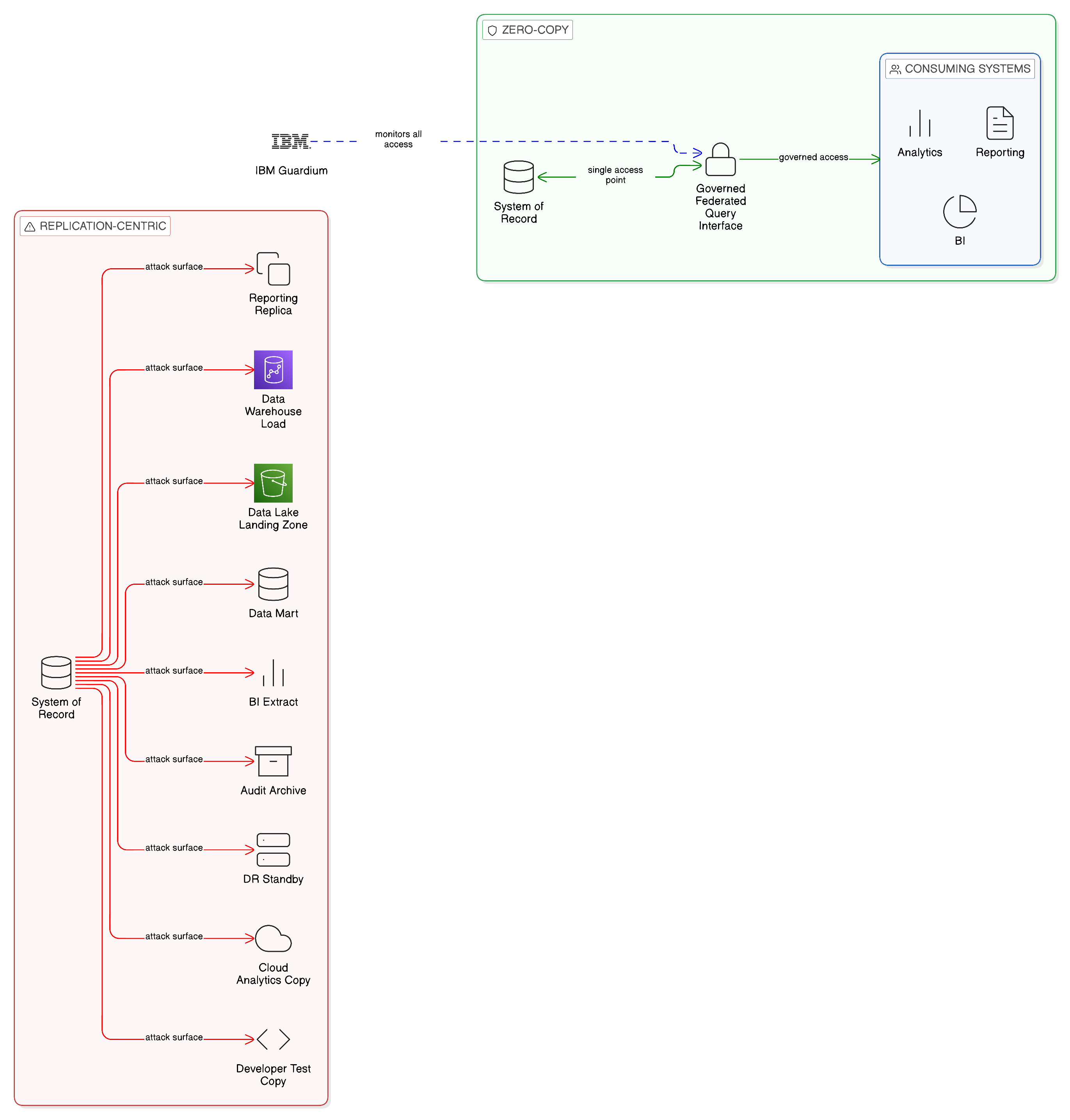
Every copy of sensitive data that exists in the enterprise is, by definition, a member of that enterprise’s data attack surface. The original system of record is one point of attack; each replica, each data mart, each analytical copy, each cache, and each intermediate staging table that contains the same data or a derivative thereof is an additional point. In a typical large enterprise operating a conventional replication-centric integration architecture, the number of such copies of any given critical dataset may run to tens or even hundreds: the operational database, the reporting replica, the data warehouse load, the data lake landing zone, the transformed data mart, the business intelligence extract, the audit archive, the disaster recovery standby, and the cloud analytics copy, to name only the most obvious. Each of these locations must be secured, each must be monitored for unauthorised access, each must be included in the enterprise’s data protection impact assessment, and each represents an independent opportunity for a breach.
The security consequences of this proliferation are compounded by the operational reality of data management in large organisations. Replicas are created for specific purposes and with specific security controls in mind, but over time the purpose evolves, the controls are not updated, and the replica continues to exist and accumulate data long after its original justification has lapsed. A data extract created for a specific analytical project that concluded three years previously may still reside in a cloud storage bucket, retaining its data but not its access controls, because no decommissioning process was followed. A developer copy of a production database, created for testing purposes, may contain full customer data including payment card information because the process of data masking for test environments was not consistently followed. A disaster recovery replica, maintained in a secondary cloud region for operational resilience, may retain data for a period longer than the applicable data retention policy permits, because the retention enforcement mechanisms were applied only to the primary system.
These are not hypothetical scenarios. The majority of significant data breaches in recent years have involved data found in locations that the breached organisation did not adequately account for in its security perimeter: cloud storage buckets without access controls, development databases with production data, backup copies discovered in unexpected locations. The attacker does not attack the most secure location in which data is held; the attacker attacks the least secure. In a replication-centric enterprise, the least secure location is almost invariably a replica rather than the primary system of record, because replicas are created rapidly, under operational pressure, and without the careful security design that the primary system receives.
The regulatory implications of this replication-driven attack surface are increasingly severe. The General Data Protection Regulation and its analogues in other jurisdictions impose specific obligations with respect to data minimisation — the principle that personal data should be processed only to the extent necessary for the specified purpose — and data security — the requirement to implement appropriate technical and organisational measures to protect personal data against unauthorised processing, accidental loss, or destruction. A replication-centric architecture is, by its nature, hostile to both principles: it creates more copies of personal data than the purposes strictly require, and it distributes that data across locations whose security controls are typically less rigorous than those of the primary system.
Zero-Copy Integration addresses the attack surface problem at the architectural level by reducing the number of data locations that must be defended. When data remains in its authoritative location and is accessed in place through governed, audited interfaces, the attack surface for that data is the authoritative system and the access control infrastructure, rather than the authoritative system plus every replica that has been created of it. This reduction is not marginal; in a large enterprise that undertakes a systematic review of its data replication practices, the reduction in the number of sensitive data locations that results from adopting Zero-Copy principles is typically substantial, and the corresponding reduction in security monitoring burden, compliance assessment scope, and breach exposure is significant.
8.2 Zero-Copy as a Security Posture
Describing Zero-Copy Integration as a security posture may seem to overstate the case for what is, fundamentally, an integration architecture philosophy. The argument merits scrutiny, however, because the security implications of Zero-Copy Integration are not merely secondary benefits of a primarily integration-focused architectural choice; they are, for many enterprises, as compelling a motivation for adoption as the economic and sovereignty benefits.
A security posture is the overall security status of an organisation’s software, networks, services, and information: it encompasses the controls in place, the residual risks accepted, and the organisation’s capacity to detect and respond to threats. Zero-Copy Integration affects each of these dimensions. It reduces residual risk by reducing the number of data locations that require defence. It simplifies control implementation by concentrating data in fewer, better-governed locations rather than distributing it across many replicas with varying security standards. And it improves the detectability of threats by concentrating data access through a smaller number of governed, monitored access points, making anomalous access patterns more visible.
The principle of least privilege, one of the foundational principles of security architecture, holds that every process, user, and system should operate with the minimum permissions necessary to perform its function. In a replication-centric integration architecture, this principle is systematically undermined by the practice of granting consuming systems access to entire datasets through replication, when those systems may actually require access to only a subset of the data. A reporting system that requires access to aggregate financial data does not, in security terms, need access to the individual transaction records from which those aggregates are derived; but if its integration with the financial system is implemented through a database replica, it inherits access to the full replica, including the individual records it does not need and should not be able to read.
Zero-Copy Integration enforces the principle of least privilege at the architectural level. When a consuming system accesses data through a federated query interface, the query is mediated by the access control policies of the Data Plane, which restrict the scope of each query to the attributes and entities that the consuming system is authorised to access. The consuming system never receives the full dataset from which its results are derived; it receives only the results of its authorised query. This mediated access model is not merely a matter of technical security control; it is a structural implementation of data minimisation at the integration layer, ensuring that the principle of accessing only what is necessary is enforced by the architecture rather than relying on the discipline of individual system operators.
The auditability of Zero-Copy access patterns is a further dimension of the security posture argument. When data is accessed in place through governed interfaces, every access event can be logged with full context: which system made the request, what data was requested, what result was returned, at what time, and under what authorisation. This audit trail is comprehensive and automatic because it is generated by the access control infrastructure, not by the individual systems making requests. In a replication-centric environment, the equivalent audit trail — tracking which system accessed which data, from which replica, at which time — is fragmentary at best. Each replica generates its own access logs, and correlating those logs to construct a complete picture of which system accessed which data across the full replication estate is a task of considerable complexity that is rarely performed proactively.
The Zero-Copy security posture also has implications for the enterprise’s ability to respond to data breach events. When a breach occurs in a replication-centric environment, one of the first and most consequential questions that must be answered is: which data was exposed? Answering this question requires identifying every replica of the breached dataset, determining what data each replica contained at the time of the breach, and establishing which of those replicas the attacker had access to. This investigation is time-consuming, incomplete, and expensive. In a Zero-Copy environment, the equivalent investigation is substantially simpler: the breached data was in its authoritative location, and the access logs of that location provide a complete record of what was accessed and by whom. The scope of the breach is defined by the access logs of the authoritative system and the governed access infrastructure, not by a forensic archaeology of an unknown number of replicas.
8.3 Zero Trust Architecture and the Zero-Copy Enterprise
The Zero Trust security model — the principle that no entity, whether inside or outside the corporate network perimeter, should be implicitly trusted, and that every access request must be verified before it is granted — has, in the years since its articulation, evolved from a theoretical framework into the dominant paradigm for enterprise security architecture in the hybrid, multi-cloud era. Its alignment with Zero-Copy Integration is not coincidental; both philosophies are responses to the same structural reality: that the traditional perimeter model of enterprise security, in which a trusted internal network is protected by a defended boundary from an untrusted external network, does not survive the dissolution of that boundary in a cloud, mobile, and distributed computing environment.
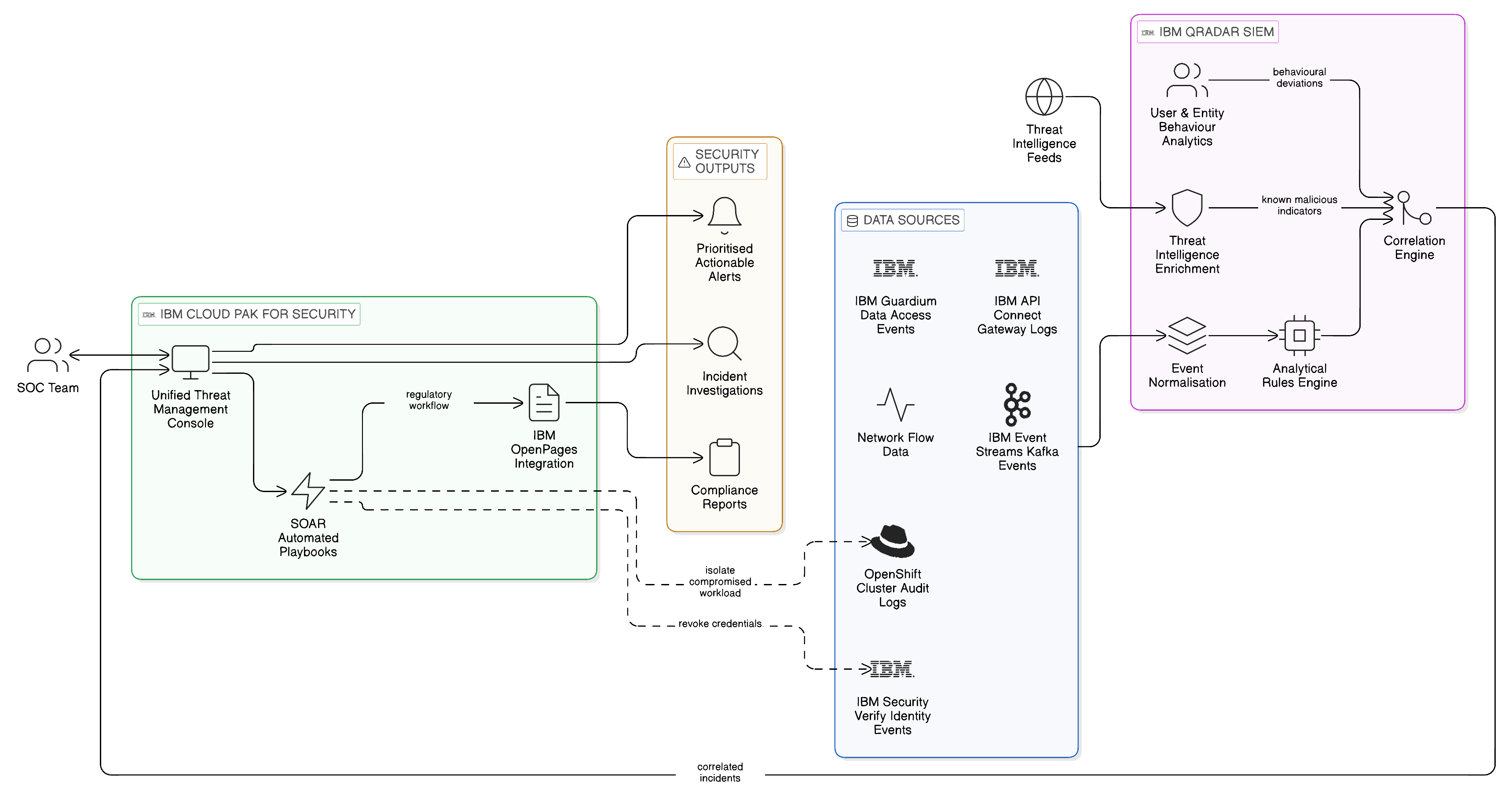
The five pillars of Zero Trust architecture — verified identity, validated device health, least-privilege access, application-layer inspection, and continuous monitoring — each find a direct expression in the Zero-Copy Integration architecture. Verified identity corresponds to the SPIFFE workload identity and IBM Security Verify identity federation infrastructure that this chapter describes. Validated device health corresponds to the Kyverno infrastructure-policy enforcement and IBM Hyper Protect attestation mechanisms that govern the integrity of the workloads accessing data. Least-privilege access corresponds to the attribute-based access control model enforced through OPA policies and IBM Knowledge Catalog’s data governance framework. Application-layer inspection corresponds to the policy enforcement at the IBM DataPower Gateway and the IBM API Connect management layer. Continuous monitoring corresponds to the IBM Guardium data activity monitoring and IBM QRadar security event management capabilities.
The Zero Trust principle of “never trust, always verify” is, in a practical sense, what the governed access model of Zero-Copy Integration implements: rather than granting consuming systems access to replicated datasets that they may then use without further verification, the Zero-Copy architecture requires every access request to pass through a governed interface that verifies the identity of the requester, evaluates the request against the applicable access policy, and returns only the authorised result. The data does not move to the consumer and remain there, trusted at rest; it is accessed dynamically, under verified conditions, at the point of need. Each access is a fresh verification event, not a perpetual grant.
This conceptual alignment between Zero Trust and Zero-Copy has a practical implication for enterprises that have already committed to a Zero Trust adoption programme: the investment in Zero-Copy Integration is not a separate architectural initiative competing with the Zero Trust programme for resources and attention; it is the data architecture expression of the same underlying security philosophy. The governance infrastructure that Zero-Copy Integration requires — data classification in IBM Knowledge Catalog, access policies in OPA, data activity monitoring in IBM Guardium — constitutes the data security layer of the enterprise’s Zero Trust architecture. Framing the investment in this way, as the data dimension of Zero Trust rather than as a standalone initiative, typically produces more aligned prioritisation and more sustained organisational commitment.
The IBM Cloud Pak for Security platform provides the integration layer through which the diverse security capabilities described in this chapter — identity management, policy enforcement, data monitoring, threat detection — are connected into a coherent Zero Trust security posture. It provides a unified threat management console that aggregates security events and intelligence from across the enterprise’s security tooling, normalises that data into a common format, and provides the analytical capabilities through which security operations teams identify patterns, investigate incidents, and orchestrate responses. For the enterprise seeking to implement the Zero Trust model with IBM’s security portfolio, Cloud Pak for Security is the connective tissue that makes the individual capabilities described in this chapter operate as a coherent system rather than a collection of separately managed tools.
8.4 Policy-as-Code: OPA, Kyverno, and Fine-Grained Control
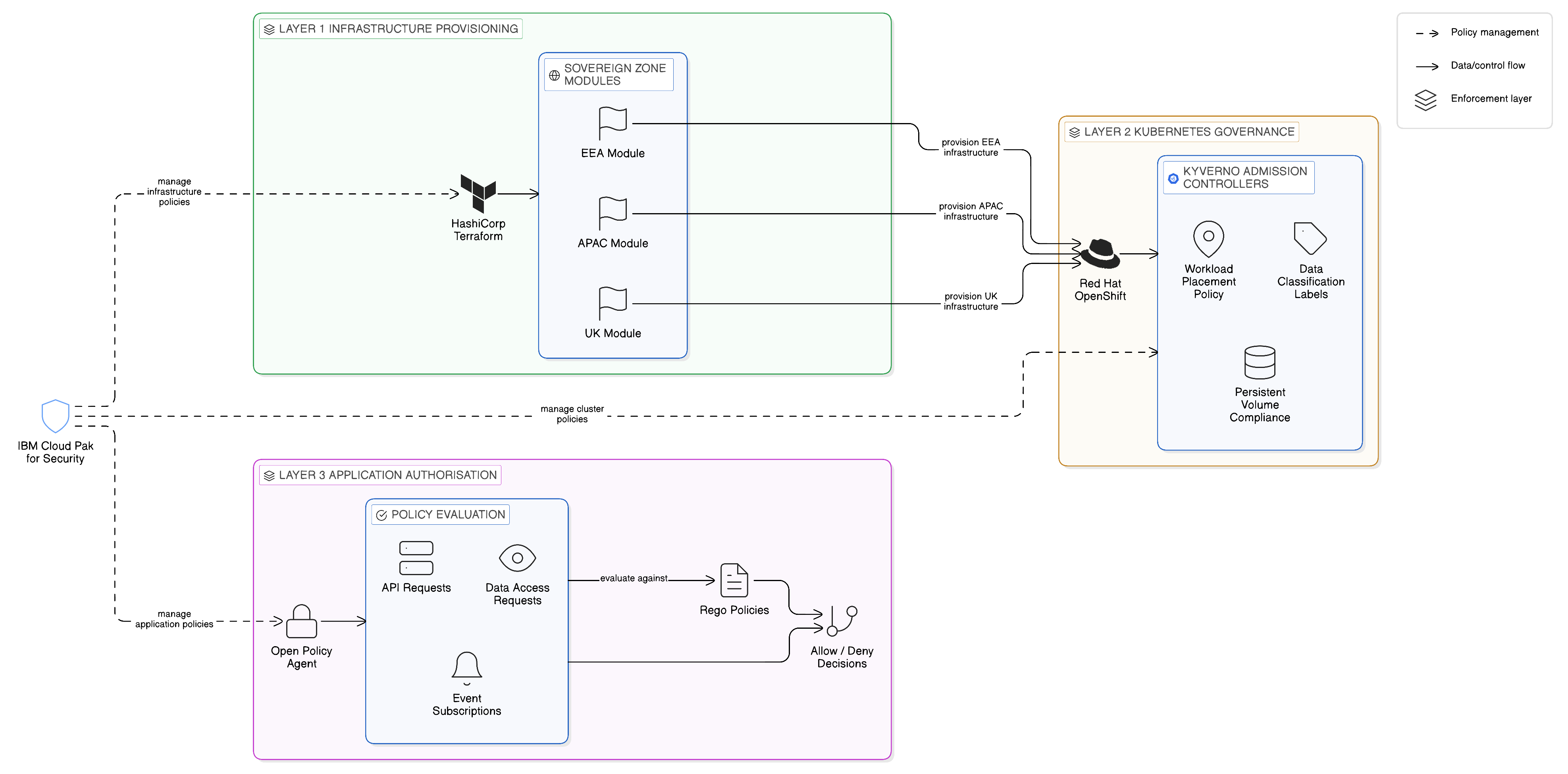
The security guarantees of a Zero-Copy architecture are only as robust as the policies that govern data access, and the enforceability of those policies depends on the mechanism through which they are implemented. Manual, process-based policy enforcement — where compliance with access policies depends on individual operators following documented procedures — is inherently fragile in the complex, rapidly-changing environment of the multi-cloud enterprise. Policies need to be expressed in a form that can be automatically evaluated and enforced by the infrastructure, not merely described in documents that operators are expected to read and follow.
Policy-as-code is the practice of expressing governance policies in machine-readable, version-controlled code that can be evaluated automatically by the infrastructure at the point at which a decision is required. Rather than a policy document that states “no European personal data may be transferred to non-European cloud regions”, a policy-as-code implementation expresses that rule in a form that the data access infrastructure evaluates for every query, every API request, and every event publication, rejecting requests that violate the rule before any data movement occurs. The policy is enforced by the system, not relied upon from the operator.
Open Policy Agent, commonly abbreviated as OPA, is the dominant open-source policy engine for cloud-native environments. It provides a general-purpose policy evaluation framework in which policies are written in a declarative language called Rego, evaluated against a request context provided by the system making the authorisation decision, and returning a decision — allow or deny, or a more complex structured response — that the requesting system enforces. OPA is deployed as a sidecar or external service alongside the applications and infrastructure components that require policy evaluation, providing a consistent, auditable policy decision point that can be queried by any component of the architecture.
In the context of Zero-Copy Integration, OPA serves as the policy engine for the Data Plane, the Application Integration Plane, and the Event Plane. For the Data Plane, OPA policies can govern which systems are permitted to query which data assets, which attributes of a dataset may be returned to a given consumer, and whether a given query context — the geographic location of the requesting system, the identity of the user on whose behalf the request is made, the time of day — is consistent with the applicable access policy. For the Application Integration Plane, OPA policies can govern which API clients may invoke which API operations, whether the content of a request or response complies with the enterprise’s data handling policies, and whether the proposed interaction crosses a jurisdictional boundary in a manner that requires additional authorisation. For the Event Plane, OPA policies can govern which event topics a given consumer may subscribe to, whether the content of a specific event may be forwarded to a consumer in a specific zone, and whether the mirroring of an event to another cluster is permitted under the applicable regulatory framework.
Kyverno is a complementary policy engine that operates specifically within Kubernetes environments, including Red Hat OpenShift, and is focused on the governance of Kubernetes resources rather than the application-level authorisation decisions that OPA addresses. Where OPA evaluates access decisions at the application level — may this system query this data, may this API request proceed — Kyverno evaluates configuration decisions at the cluster level: may this workload be deployed in this namespace, does this pod specification comply with the enterprise’s security policies, does this persistent volume claim satisfy the data locality constraints imposed by the applicable sovereignty framework. Kyverno policies are expressed as Kubernetes resources, using the familiar YAML syntax of Kubernetes configuration, and are evaluated by Kyverno admission controllers that intercept Kubernetes API requests before they are processed by the cluster.
In a sovereign, multi-cloud OpenShift deployment, Kyverno provides the infrastructure-level policy enforcement that complements OPA’s application-level enforcement. A Kyverno policy can prevent a workload that processes European personal data from being scheduled on cluster nodes located outside the European sovereign zone; another policy can prevent the creation of persistent volumes that would store data in a non-compliant storage class; a third policy can ensure that all deployed containers carry the required data classification labels before they are permitted to access governed data sources. Together, these infrastructure-level policies create a governed deployment environment in which the placement and configuration of workloads is automatically constrained by the applicable sovereignty and security policies, reducing the reliance on manual review and operator discipline that characterises less mature governance approaches.
The combination of OPA for application-level authorisation and Kyverno for infrastructure-level governance provides a comprehensive policy-as-code framework for the Zero-Copy enterprise. Both tools integrate with the Red Hat OpenShift platform and with IBM’s governance infrastructure, allowing the policies expressed in OPA and Kyverno to be managed through the same governance tooling that manages the enterprise’s broader data and integration policies. IBM’s Cloud Pak for Security provides the management layer through which OPA and Kyverno policies can be authored, tested, deployed, and audited in a consistent manner across the enterprise’s full portfolio of cloud environments, ensuring that the policy estate itself is under governance control and does not accumulate the technical debt and inconsistency that unmanaged policy proliferation creates.
A third expression of the policy-as-code discipline operates at the infrastructure provisioning layer, beneath the Kubernetes cluster on which OPA and Kyverno operate, and is provided by HashiCorp Terraform. Whilst OPA governs what data access is permitted at runtime and Kyverno governs what workloads may be deployed to an existing cluster, Terraform governs what infrastructure is created in the first place. In the sovereign zone topology described throughout this book, each zone’s OpenShift cluster, its network configuration, its storage classes, and its security group policies must be provisioned consistently and reproducibly: a zone whose underlying infrastructure deviates from the declared specification will produce governance policy discrepancies that OPA and Kyverno surface but cannot themselves remediate, because the underlying cause is an infrastructure misconfiguration that exists below the Kubernetes layer. Terraform addresses this by declaring the desired state of the infrastructure in version-controlled configuration files — an Infrastructure-as-Code model that is the direct analogue of the GitOps configuration management model applied to integration components in Chapter 10. The sovereign zone topology is declared in Terraform modules: a module for the EEA zone specifies, in its provider configuration, that only infrastructure within EEA-compliant regions may be provisioned, making it architecturally impossible for an operator to accidentally place a component of the European zone on non-EEA infrastructure. A module for the UK zone specifies UK-jurisdiction compute and storage, and so forth across the enterprise’s full sovereign topology. When a new jurisdiction requires a new sovereign zone — as India’s DPDP Act or the EU AI Act creates new compliance requirements, as discussed in Chapter 19 — the new zone is provisioned by parameterising the existing Terraform module rather than by constructing the infrastructure manually, ensuring governance consistency from the first moment of the zone’s existence. The Terraform state, maintained in version-controlled repositories, provides the authoritative infrastructure configuration audit record that the GitOps pipeline for application configuration complements: together, they provide a complete, auditable, reproducible declaration of the enterprise’s sovereign deployment topology from the infrastructure layer upwards.
8.5 Attribute-Based Access Control for Federated Data
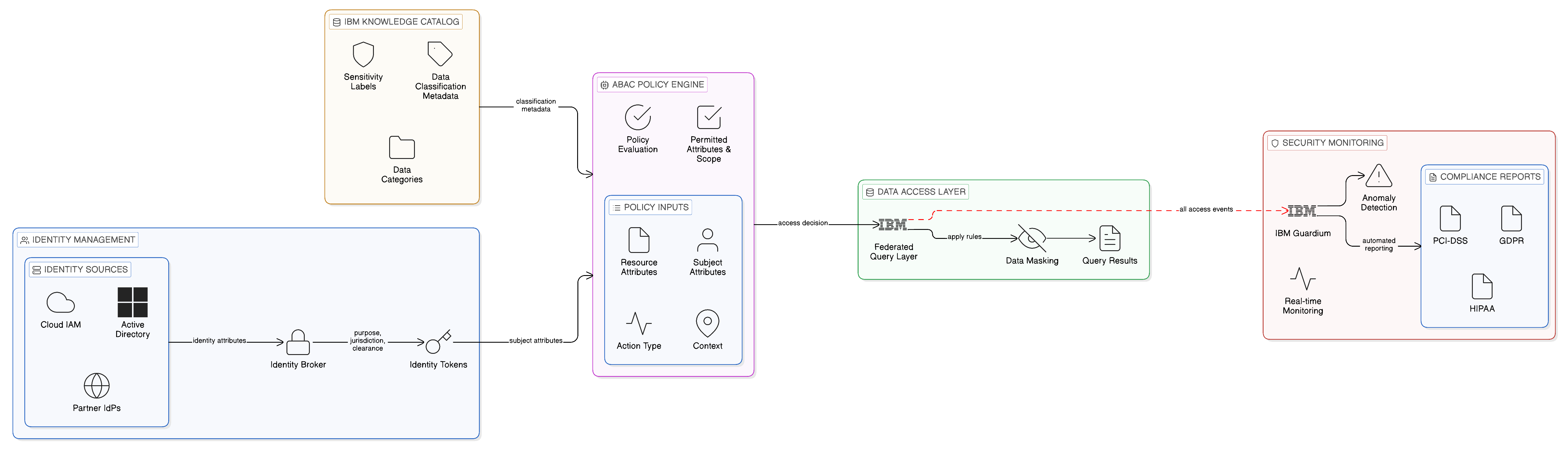
The governance model that underlies fine-grained data access control in the Zero-Copy enterprise is attribute-based access control, commonly abbreviated as ABAC. It represents a significant evolution beyond the role-based access control model that has dominated enterprise identity and access management for the past two decades, and its adoption is essential to the realisation of the data minimisation and least-privilege objectives that the Zero-Copy security posture requires.
Role-based access control assigns permissions to roles and assigns users to roles, so that a user’s access rights are determined by the roles they hold. This model is well-suited to environments in which the access requirements are relatively stable and can be expressed as a manageable number of discrete roles: a financial analyst role that grants access to financial reports, an HR administrator role that grants access to personnel records, a system operator role that grants access to operational monitoring dashboards. For these relatively coarse-grained access requirements, role-based control is operationally practical and sufficiently expressive.
The data access requirements of the Zero-Copy enterprise are, however, considerably more fine-grained than role-based control can readily accommodate. A consumer that is authorised to access customer data for the purpose of fraud detection should, in principle, be restricted to the specific attributes of the customer record that are relevant to fraud detection — transaction history, account status, device identifiers — and should not receive attributes that are irrelevant to that purpose, such as the customer’s marketing preferences or their detailed personal history. A consumer that is authorised to access the same customer records for the purpose of regulatory reporting may require a different subset of attributes and may be permitted to access records from a different date range. A consumer operating within a European jurisdiction may be authorised to access personal data attributes that a consumer operating in another jurisdiction, whose regulatory framework imposes different constraints, may not.
These requirements cannot be expressed as a manageable set of roles in a role-based access control system: the number of roles required to represent the full matrix of purpose-specific, attribute-specific, jurisdiction-specific access permissions would be unmanageably large. Attribute-based access control addresses this complexity by evaluating access decisions dynamically against a policy that references the attributes of the requesting subject, the requested resource, the action being performed, and the environmental context in which the request is made. An ABAC policy can express “a system with the attribute purpose=fraud-detection, operating in the context jurisdiction=EU, may access customer records with the attributes transaction_history and account_status but not marketing_preferences or biometric_data” without requiring a separate role to be defined for each combination of purpose, jurisdiction, and attribute set.
IBM Security Verify, IBM’s enterprise identity and access management platform, provides the ABAC capabilities required to implement fine-grained data access control in the Zero-Copy enterprise. It supports the expression of access policies that reference attributes drawn from multiple sources — the identity provider, the data classification system, the environmental context — and evaluates those policies at request time to make dynamic authorisation decisions. Its integration with IBM Knowledge Catalog, which holds the data classification and sensitivity metadata for the enterprise’s data assets, enables access policies to reference the actual sensitivity classifications of the data being requested, rather than relying on the requesting system to declare the sensitivity of the data it is accessing.
The integration of ABAC with the Data Plane creates what may be termed a policy-mediated data access model: every query to a federated data source is evaluated against the applicable ABAC policy before execution, and the policy determines not merely whether the query is permitted but also what scope of data may be returned — which attributes, which date ranges, which entity populations. IBM Knowledge Catalog’s integration with the query execution infrastructure of IBM watsonx.data enables this policy evaluation to occur at the query planning stage, before any data is read from the source, ensuring that the access control policy is enforced at the earliest possible point in the data access lifecycle.
8.6 IBM Guardium: Data Security and Compliance Across the Enterprise
The reduction in attack surface that Zero-Copy Integration achieves is a significant security benefit, but it does not eliminate the requirement for continuous monitoring and auditing of data access. Data held in its authoritative location remains subject to the full range of threats that any data store faces: privileged insider access, compromised application credentials, misconfigured access controls, and external attack on the data layer itself. The Zero-Copy architecture reduces the number of locations at which these threats must be managed; it does not eliminate the threats themselves. A comprehensive data security capability is therefore a complement to the Zero-Copy architectural discipline, not a substitute for it.
IBM Guardium is IBM’s enterprise data security and compliance platform, providing continuous monitoring of data access activity across a broad range of data repositories, including relational databases, data warehouses, cloud data stores, and big data platforms. It operates through lightweight software agents deployed at the data layer that intercept and record all data access activity — every query, every stored procedure call, every administrative action — and report that activity to the Guardium central management infrastructure for analysis, alerting, and audit.
The primary capabilities of IBM Guardium in the context of Zero-Copy Integration are threefold. First, it provides real-time detection of anomalous access patterns: access to sensitive data at unusual hours, access by accounts that do not normally access a particular data store, bulk data retrieval that may indicate data exfiltration, and privileged user activity that bypasses normal application access paths. These anomalies can be detected and alerted in real time, allowing the security operations team to investigate and respond before a potential breach has progressed beyond its initial stage.
Second, Guardium provides compliance reporting against a comprehensive library of regulatory frameworks, including GDPR, the Payment Card Industry Data Security Standard, the Health Insurance Portability and Accountability Act, and a wide range of national and sectoral data protection regimes. These reports are generated automatically from the activity data captured by the Guardium agents, without requiring manual data collection or the assembly of audit evidence from disparate log sources. In a Zero-Copy architecture, where data access is concentrated through a smaller number of governed access points, the Guardium monitoring infrastructure benefits from this concentration: rather than monitoring access to dozens of replicas across the estate, it monitors access to the authoritative data sources and the governed access infrastructure through which all legitimate access occurs.
Third, Guardium provides data discovery and classification capabilities that allow the enterprise to identify where sensitive data resides, including in locations that may not have been intentionally designed to hold sensitive data — the development database that was populated with production data, the analytical staging table that was not purged after project completion, the cloud storage bucket that was created as a temporary working area and was never decommissioned. This discovery capability is particularly valuable during the transition to a Zero-Copy architecture, when the enterprise is undertaking the systematic review of its replication estate that the adoption of Zero-Copy principles requires. Guardium’s discovery findings provide the empirical foundation for that review, identifying the full scope of the sensitive data holdings that the enterprise must manage and informing the prioritisation of remediation efforts.
IBM Guardium Insights, the cloud-native evolution of the Guardium platform, extends these capabilities to cloud-native data environments, integrating with the managed database services of the major public cloud providers and providing a unified security monitoring view across on-premises databases and cloud data stores simultaneously. In a hybrid, multi-cloud enterprise that is in the process of adopting Zero-Copy Integration, this unified view is essential: the transition period during which both replication-centric and Zero-Copy integration patterns coexist in the same enterprise is the period of greatest security complexity, because the full replication estate continues to exist whilst the governed Zero-Copy access infrastructure is being established.
8.7 IBM Hyper Protect and Confidential Computing
The protections described to this point in the chapter address the security of data at rest — in authoritative data stores and the replicas that the Zero-Copy approach seeks to eliminate — and data in transit — through the encryption of network communications between systems. A third dimension of data protection has emerged in recent years as a critical requirement for enterprises processing highly sensitive data: the protection of data whilst it is in use, during the processing operations in which it is necessarily decrypted and held in memory.
Data in use is, in conventional computing environments, unprotected. When an application decrypts data to process it, the decrypted data is held in the application’s memory space, accessible to the operating system, the hypervisor, and any process that can access the host system’s memory. In a cloud computing environment, this means that the cloud provider’s administrators — or any attacker who has compromised the cloud provider’s infrastructure — have, in principle, access to the decrypted data whilst it is being processed. For highly sensitive data — encryption keys, personal health information, financial trading strategies, classified government data — this exposure may be unacceptable, regardless of the contractual assurances the cloud provider offers.
Confidential computing addresses this exposure through hardware-based trusted execution environments: isolated regions of processor memory, called enclaves, in which code and data are encrypted at the hardware level and protected from access by any software outside the enclave, including the operating system and hypervisor. Code executing within a confidential computing enclave can decrypt and process sensitive data without that data being accessible to the host environment, providing a verifiable guarantee — through a process called remote attestation, in which the hardware produces a signed certificate of the enclave’s configuration and the integrity of the code running within it — that the processing environment is as the enterprise intends and has not been modified or compromised.
IBM Hyper Protect is IBM’s confidential computing platform, designed for enterprise workloads that require the highest levels of data-in-use protection. Built on IBM’s Secure Service Container technology, which runs on IBM LinuxONE and IBM Z mainframe infrastructure, Hyper Protect provides an environment in which workloads are deployed in a verifiable, integrity-protected execution environment that IBM’s own operations staff cannot access. The workload owner holds the encryption keys; IBM’s infrastructure provides the execution environment but cannot read the data or code that the workload processes. This technical exclusion of the cloud provider from the data-in-use layer is, for the most sensitive regulated industries, the capability that makes cloud deployment of highly sensitive workloads acceptable in principle.
IBM Hyper Protect Virtual Servers extends this capability to containerised workloads, allowing enterprises to deploy containerised applications in confidential computing environments without requiring the application to be specifically redesigned for enclave execution. The container image is encrypted, and the Secure Service Container environment ensures that only the encrypted container image that the enterprise has approved can be deployed in the Hyper Protect environment, providing supply chain security for the container as well as runtime protection for the data it processes.
In the context of Zero-Copy Integration, confidential computing has a specific and important role in the design of federated query execution. When a Zero-Copy federated query is executed against data held in a sensitive authoritative source, the query processing involves decrypting and reading data from the source, applying filter and aggregation operations to produce the query result, and returning only the result to the requesting consumer. In a conventional computing environment, the intermediate state — the decrypted data read from the source, before filtering and aggregation — is visible to the host environment in which the query processing occurs. In a confidential computing environment, the query processing can be executed within a Hyper Protect enclave, ensuring that the intermediate state is protected from the host environment and that only the approved query logic, verified through remote attestation, is applied to the sensitive data. This architecture — federated query execution within a confidential computing enclave — addresses a class of concern that may otherwise prevent enterprises from adopting Zero-Copy federated access for their most sensitive data assets: the concern that the query execution infrastructure, even if operated by the enterprise itself, cannot be fully trusted to protect the intermediate state.
8.8 Identity Federation Across the Multi-Cloud Enterprise
The security architecture of the Zero-Copy enterprise is only as strong as its identity management foundation. The access control policies described in this chapter — OPA policy decisions, ABAC attribute evaluations, Guardium access monitoring, Hyper Protect enclave attestation — all depend on the reliable identification of the entities making data access requests: which user, which application, which service, which workload is requesting access, and what authoritative attributes can be asserted about that entity. In a single-cloud or single-domain environment, this identification is managed by a single identity provider whose assertions are trusted throughout the environment. In the hybrid, multi-cloud enterprise, the reality is substantially more complex.
A large enterprise operating across multiple cloud providers, with on-premises systems, partner integrations, and edge deployments, typically has multiple identity providers: an on-premises Active Directory or LDAP directory for corporate user identities, cloud provider-specific IAM systems for workload identities within each cloud platform, partner-specific identity systems for external integrations, and device identity systems for edge and IoT deployments. The challenge of identity federation — creating a coherent, mutually trusted identity infrastructure from these disparate sources — is one of the most practically difficult aspects of multi-cloud security architecture.
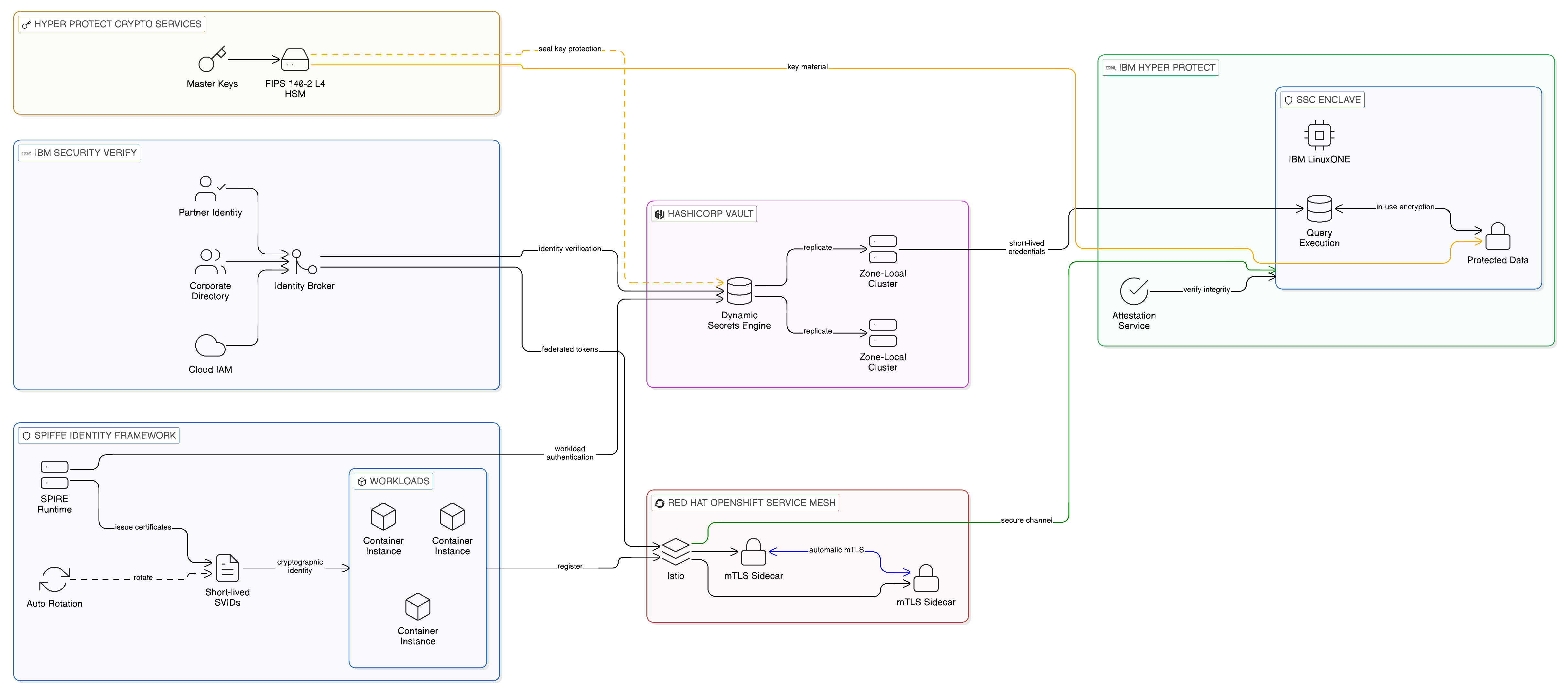
IBM Security Verify provides the identity federation capabilities required to address this challenge. It acts as an identity broker, consuming identity assertions from multiple upstream identity providers — corporate directories, cloud IAM systems, partner identity federations — and producing standardised, enriched identity tokens that the enterprise’s data access infrastructure trusts for access control decisions. The standardisation of identity across heterogeneous sources is essential to the ABAC model described in the preceding section: if the access control policy references the attribute jurisdiction=EU to determine which data a requesting system may access, the system by which the jurisdiction attribute is established and asserted for a given requesting workload must be consistent and trustworthy across all the cloud environments in which that workload might operate.
The SPIFFE standard — Secure Production Identity Framework for Everyone — and its reference implementation SPIRE provide the workload identity layer that is required for service-to-service authentication in the multi-cloud, Zero Trust environment. SPIFFE defines a standard for assigning cryptographic identities to individual workloads — a specific container instance, a specific function, a specific service deployment — that can be verified by any other workload without requiring a central certificate authority that must be trusted by all cloud environments. SPIFFE identities are expressed as SPIFFE Verifiable Identity Documents, short-lived cryptographic certificates that are automatically rotated by the SPIRE runtime without requiring manual certificate management. In a Zero-Copy enterprise, SPIFFE workload identities provide the verifiable, cross-cloud service authentication layer that ABAC policies and OPA access decisions require: every data access request carries a cryptographically verifiable identity that the access control infrastructure can evaluate against the applicable policy without trusting the requesting workload to accurately self-identify.
Red Hat OpenShift Service Mesh, built on the Istio service mesh framework, integrates SPIFFE workload identities as its default mutual TLS authentication mechanism, providing automatic certificate issuance and rotation for every service deployed within the mesh. This integration means that enterprises deploying their integration workloads on OpenShift inherit SPIFFE-based workload authentication as a default characteristic of the platform, rather than requiring a separate implementation project. Combined with the OPA integration capabilities of the Istio service mesh — which allow OPA policy evaluation to be invoked for every service-to-service interaction within the mesh — OpenShift Service Mesh provides a comprehensive, automatically enforced access control layer for the Application Integration and Event planes of the Zero-Copy architecture.
Beneath the identity layer that SPIFFE and IBM Security Verify provide, a further and often underestimated layer of the security architecture governs the lifecycle of the credentials that the integration fabric’s components use to authenticate with one another and with the data sources they access: the API keys for SaaS platform connections, the OAuth client credentials for API consumers, the database passwords for data sources accessed through the integration layer, and the TLS certificates presented by each integration component. In a large enterprise integration estate, the number of such credentials is substantial, and the conventional practice of distributing static credentials — embedding them in environment variables, configuration files, or Kubernetes secrets — creates a credential proliferation problem that mirrors, at the security layer, the data replication problem that the Zero-Copy architecture addresses at the integration layer. A static credential that is distributed to many integration components exists in many locations simultaneously; when it must be rotated — on schedule or in response to a compromise — every location must be updated, and a missed update leaves a stale credential that either breaks the integration it governs or, more dangerously, remains valid for an attacker who has extracted it from a configuration artefact. The auditing of static credentials is equally limited: it is typically impossible to determine, with confidence, which integration components hold a copy of a given credential and which have been updated following a rotation.
HashiCorp Vault addresses this credential proliferation through the dynamic secrets model: rather than distributing static credentials to integration components, Vault generates short-lived, purpose-specific credentials on demand through its secrets engine API, delivers them directly to the requesting component at execution time, and revokes them automatically when they expire or when the requesting workload’s session ends. An IBM App Connect integration flow that requires access to a database does not carry a stored password; it carries the Vault authorisation to request a short-lived database credential from Vault’s database secrets engine at the point of each invocation. The credential exists only for the duration of the flow’s execution, has never been stored in a configuration file or environment variable, and is automatically invalid once the session expires. The blast radius of a credential compromise is bounded by the dynamic scope of Vault’s issuance: a compromised short-lived credential expires within minutes, and the specific workload whose Vault authorisation was compromised can be revoked instantly without requiring the rotation of any shared static credential. Vault’s audit log — every credential request, every issuance, every revocation — provides the tamper-evident record of which workload accessed which secrets engine at which time, complementing IBM Guardium’s data access audit at the database layer with a credential access audit at the secrets management layer.
The sovereign zone topology creates a specific configuration requirement for Vault: zone-local credential issuance. In a Zero-Copy architecture where each sovereign zone’s integration components must operate without depending on cross-zone connectivity for normal operations, a centralised Vault instance that all zones query for credentials is a resilience liability — a cross-zone dependency on the critical path of integration flow execution. Vault’s multi-cluster federation capability — deploying a Vault cluster local to each sovereign zone, with policy and mount configuration replicated across clusters whilst actual secret values are generated and stored within the issuing zone — allows the enterprise to maintain centralised credential policy governance through the same model as its integration fabric governance, whilst ensuring that credential issuance remains local to each sovereign zone. The relationship between Vault and IBM Hyper Protect Crypto Services completes this picture: Vault’s seal key — the master key that protects Vault’s own encryption — can be held in IBM Hyper Protect Crypto Services’ HSM, ensuring that the root of the credential security chain is itself protected by hardware-bound key material with the highest available assurance level.
8.9 Encryption: In Transit, At Rest, and In Use
A complete account of the security architecture of the Zero-Copy enterprise requires attention to encryption across all three states of data: in transit, at rest, and in use. Encryption in transit and at rest are well-established practices in enterprise security, and most organisations with mature security programmes have policies and implementations that address both. The specific considerations that arise in the context of Zero-Copy Integration are worth examining, however, because the distributed, multi-cloud character of the architecture creates specific challenges that simpler, single-environment architectures do not face.
Encryption in transit — the encryption of data as it moves across networks between systems — is implemented in the Zero-Copy enterprise through the consistent application of Transport Layer Security across all communication channels: between API consumers and gateways, between gateways and upstream services, between event producers and Kafka brokers, between Kafka brokers and consumers, and between federated query engines and the data sources they query. In a multi-cloud enterprise, the challenge is ensuring that TLS is consistently applied across the full communication landscape, including at the boundaries between cloud environments where traffic crosses through network infrastructure that may not be under the enterprise’s direct control.
Mutual TLS — in which both the client and the server present cryptographic certificates to authenticate to one another — provides a stronger authentication guarantee than one-way TLS and is recommended for all service-to-service communication within the Zero-Copy architecture. The SPIFFE workload identity framework described in the preceding section provides the certificate infrastructure for mutual TLS between workloads, ensuring that every service-to-service communication within the OpenShift environment is authenticated in both directions and that the identity of both parties is cryptographically verifiable.
Encryption at rest — the encryption of data in persistent storage — is essential for the authoritative data stores that the Zero-Copy architecture preserves in their canonical locations. IBM Guardium Key Lifecycle Manager provides centralised management of the encryption keys used to encrypt data at rest across the enterprise’s heterogeneous storage estate, ensuring that key management — rotation, revocation, audit — is subject to the same governance discipline as the data it protects. The management of encryption keys by the enterprise rather than by the cloud provider is a significant sovereignty consideration: if the cloud provider holds the encryption keys, the cloud provider has the technical capability to access the encrypted data. If the enterprise holds the keys, that capability is removed.
The bring-your-own-key and hold-your-own-key models, in which the enterprise supplies the encryption keys that the cloud provider uses to encrypt data at rest but retains exclusive control over those keys, represent important intermediate positions between full cloud provider key management and entirely on-premises key management. IBM Key Protect and IBM Hyper Protect Crypto Services provide these capabilities for workloads deployed in IBM Cloud, ensuring that the enterprise retains key sovereignty over its cloud-resident data even when using IBM’s managed cloud storage services. IBM Hyper Protect Crypto Services, in particular, uses hardware security modules backed by IBM Z mainframe technology to provide key management with a certified level of hardware security that exceeds the key protection standards of most competitive cloud key management services.
 Encryption in use — the protection of data during processing — has been addressed in the preceding section on confidential computing. It is worth noting here that confidential computing represents the completion of the encryption lifecycle: when data is protected in transit, at rest, and in use, the only state in which it is unencrypted is within the verified execution environment in which it is being legitimately processed. This complete encryption lifecycle is, for the most sensitive data assets, the technical foundation upon which the enterprise’s assurance to regulators, partners, and customers that their data is protected can rest.
Encryption in use — the protection of data during processing — has been addressed in the preceding section on confidential computing. It is worth noting here that confidential computing represents the completion of the encryption lifecycle: when data is protected in transit, at rest, and in use, the only state in which it is unencrypted is within the verified execution environment in which it is being legitimately processed. This complete encryption lifecycle is, for the most sensitive data assets, the technical foundation upon which the enterprise’s assurance to regulators, partners, and customers that their data is protected can rest.
8.10 Secure Access Patterns for Federated Data
The security mechanisms described in this chapter — policy-as-code, ABAC, identity federation, data activity monitoring, and confidential computing — combine in the Zero-Copy architecture to support a set of secure access patterns that collectively define how the enterprise’s data assets are made available to authorised consumers without creating the replication-driven attack surface that conventional integration architectures generate. Three such patterns merit specific examination.
8.10.1 Zero-Copy Secure Data Zones
The secure data zone pattern addresses the requirement to make sensitive data available to analytical workloads without either replicating the data into an analytical environment or granting the analytical environment unrestricted access to the production data store. It is relevant wherever highly sensitive data — patient health records, financial trading data, classified government information — must be analysed by workloads that operate in environments whose security controls are less rigorous than those of the production system.
In the secure data zone pattern, a governed query interface is established between the analytical environment and the authoritative data source. All queries from the analytical environment are mediated by this interface, which enforces the applicable ABAC policy before forwarding the query to the data source. The interface is designed to return only aggregated or anonymised results to the analytical environment: individual records that contain directly identifying personal data are not returned; only statistical aggregates and anonymised individual records are permitted to cross the zone boundary. IBM watsonx.data’s data masking and query governance capabilities support this pattern, allowing the enterprise to define data masking rules that are applied automatically to all query results before they are returned to the requesting consumer.
The secure data zone pattern is complemented by the confidential computing pattern described in the preceding section: by executing the query processing and anonymisation operations within a confidential computing enclave, the enterprise ensures that not only the returned results but also the intermediate processing state is protected from the analytical environment. The analytical workload receives only the anonymised results that the governance policy permits; the raw data from which those results are derived is never exposed to the analytical environment, even during the processing of the query.
8.10.2 Cross-Cloud Attribute-Based Access Control Enforcement
The cross-cloud ABAC enforcement pattern addresses the challenge of maintaining consistent access control governance across the multiple cloud environments of the hybrid, multi-cloud enterprise, where each cloud platform operates its own native IAM system with its own policy model and its own access control evaluation mechanisms.
In a conventional multi-cloud security architecture, the access control policies for each cloud environment are expressed in that environment’s native IAM policy language and evaluated by that environment’s native IAM service. The result is a set of access control policies that are expressed differently in each cloud environment, evaluated by different policy engines, and audited through different monitoring interfaces, with no guarantee of consistency between environments. An access policy that permits a specific analytical workload to access customer data for fraud detection purposes may be correctly implemented in one cloud environment and incorrectly implemented — too permissive, too restrictive, or simply absent — in another.
The cross-cloud ABAC enforcement pattern addresses this inconsistency by establishing a single, authoritative policy expression layer — implemented in OPA — that defines the enterprise’s data access policies in a platform-independent manner, and deploying OPA evaluation sidecars alongside every data access interface across all cloud environments. Each cloud environment’s native IAM system handles authentication — verifying the identity of the requesting entity — whilst OPA handles authorisation — determining whether the authenticated entity is permitted to perform the requested operation under the enterprise’s cross-cloud access policies. This separation of authentication and authorisation, with OPA serving as the universal authorisation layer, ensures that the enterprise’s access control policies are expressed once, maintained centrally, and enforced consistently across every cloud environment in which data is accessed.
8.10.3 Sovereign Audit Trails with Tamper-Evident Lineage
The sovereign audit trail pattern addresses the requirement — common in regulated industries and increasingly mandated by regulators in the context of GDPR and its analogues — to maintain a comprehensive, tamper-evident record of all data access events that can be produced as evidence of regulatory compliance.
In a replication-centric architecture, the construction of a comprehensive audit trail is complicated by the dispersion of data access across multiple replica locations, each maintaining its own access logs in potentially incompatible formats. The consolidation of these logs into a coherent audit trail requires significant operational effort and is subject to the gaps and inconsistencies that arise when access logs are not designed for interoperability. In a Zero-Copy architecture, where all data access occurs through a smaller number of governed interfaces, the audit trail is more compact and more coherent: every access event passes through a governed interface that logs it in a consistent format.
IBM Guardium provides the data activity monitoring layer that captures every access event at the data store level, independent of the application that generated the access. OpenLineage, the open standard for data lineage tracking, provides the mechanism for capturing lineage information — which processes accessed which data, in what sequence, to produce which outputs — across the Data Plane, Application Integration Plane, and Event Plane of the Zero-Copy architecture. IBM Knowledge Catalog integrates OpenLineage metadata with its enterprise data governance capabilities, providing a searchable, queryable lineage graph that allows compliance teams to reconstruct the complete data access history for any given dataset.
The tamper-evidence requirement — the assurance that audit logs have not been modified after the fact, either to conceal unauthorised access or to fabricate the appearance of compliance — is addressed through the cryptographic integrity protection of the audit log. IBM Guardium’s audit data can be signed with cryptographic keys held in IBM Hyper Protect Crypto Services, ensuring that any modification to the audit records after their initial capture is detectable. This cryptographic integrity protection provides the technical foundation for the assertion that the audit trail presented to regulators accurately reflects what occurred, and has not been selectively edited to conceal non-compliant activity.
8.11 IBM QRadar and Security Operations Centre Integration
The security mechanisms described in this chapter — policy enforcement, access control, data activity monitoring, confidential computing — constitute the preventive and detective layers of the Zero-Copy security architecture. They are designed to prevent unauthorised access, detect anomalous behaviour, and produce audit records that demonstrate compliance. However, no security architecture, however well designed, can eliminate entirely the possibility of security incidents: novel attack vectors emerge, legitimate credentials are compromised, insider threats manifest in ways that policy-based controls do not anticipate. The enterprise requires, therefore, not only a preventive and detective security capability but a response capability: the ability to identify when a security incident is occurring, understand its scope and nature, and act to contain it before it escalates.
IBM QRadar is IBM’s Security Information and Event Management platform, providing the centralised threat detection and investigation capability that the security operations function requires. It collects security event data from across the enterprise’s full technology estate — network devices, servers, applications, cloud services, identity management systems, and data security tools including IBM Guardium — normalises that data into a common format, and applies analytical rules and machine learning models to identify patterns that indicate potential security incidents. Alerts generated by QRadar are prioritised and routed to the security operations team for investigation and response, reducing the volume of raw security events to a manageable set of actionable alerts.
The integration of IBM QRadar with IBM Guardium is particularly relevant in the context of Zero-Copy Integration. Guardium captures data access events at the database level; QRadar provides the correlation engine that connects those events to other security signals from across the estate. A sequence of events that, viewed in isolation, might appear benign — a user authenticating from an unusual location, followed by a query to a sensitive data store, followed by a large data download — becomes a suspicious pattern when the events are correlated across the timeline and compared against the user’s normal behaviour baseline. QRadar’s user and entity behaviour analytics capability, which builds behavioural baselines for users and systems and alerts when behaviour deviates significantly from those baselines, is directly applicable to the insider threat detection challenge that is relevant in any governed data access environment.
The integration of IBM QRadar with IBM Cloud Pak for Security provides the threat intelligence enrichment and automated response capabilities that mature security operations require. Threat intelligence feeds — information about known malicious IP addresses, domains, file hashes, and attack techniques — enrich QRadar’s analysis, improving the accuracy of threat detection and reducing false positive rates. IBM’s Security Orchestration, Automation and Response capabilities, available through the Cloud Pak for Security platform, enable the automated execution of defined response playbooks in response to specific alert types: automatically isolating a compromised workload, revoking the access credentials of a suspected insider threat, or triggering a governance workflow in IBM OpenPages to initiate the incident management process required by the enterprise’s regulatory obligations.
For the technology leader considering the security investment implications of Zero-Copy Integration, the IBM QRadar and Security Operations Centre integration provides an important perspective: the concentration of data access through governed interfaces that Zero-Copy Integration achieves does not merely reduce the attack surface; it also improves the signal-to-noise ratio of security monitoring. When data access is dispersed across dozens of replicas, each generating its own access logs in its own format, the security operations team faces the challenge of correlating signals across a vast and heterogeneous dataset. When data access is concentrated through a smaller number of governed, consistently logged interfaces, the signals that indicate suspicious behaviour are more visible, more consistent in format, and more amenable to automated correlation and analysis. The investment in Zero-Copy Integration thus improves the return on the enterprise’s security operations investment, producing more actionable intelligence from the same monitoring infrastructure.
8.12 The Security Architecture in the Enterprise Zero-Copy Context
The security components described in this chapter — Zero Trust architecture as the overarching model, policy-as-code through OPA and Kyverno, ABAC through IBM Security Verify, data activity monitoring through IBM Guardium, confidential computing through IBM Hyper Protect, identity federation through SPIFFE and IBM Security Verify, encryption across the data lifecycle, and threat detection through IBM QRadar — collectively constitute the security architecture of the enterprise Zero-Copy Integration capability. This architecture does not operate independently of the Data, Application Integration, and Event planes described in preceding chapters; it is woven through each of them, enforcing at every plane the access control, monitoring, and audit requirements that the enterprise’s regulatory and risk management obligations impose.
The relationship between the security architecture and the Zero-Copy philosophy is reciprocal. The Zero-Copy philosophy reduces the attack surface that the security architecture must protect, by eliminating the replication-driven proliferation of sensitive data locations. The security architecture enables the Zero-Copy philosophy to be realised in practice, by providing the access control, monitoring, and audit mechanisms that make governed, in-place data access trustworthy and demonstrably compliant. Neither is sufficient without the other: a Zero-Copy architecture without a robust security layer is an architecture that relies on the correctness of its access control policies without verifying their enforcement; a security architecture applied to a replication-centric estate is an architecture that must defend a much larger attack surface than necessary.
For the CIO and CTO, the practical implication of this architecture is that the investment in Zero-Copy Integration and the investment in enterprise security are complementary and mutually reinforcing, not competing priorities. The enterprise that invests in establishing governed, in-place data access patterns simultaneously reduces its security monitoring burden, simplifies its compliance audit preparation, and narrows the scope of its data protection impact assessments. The enterprise that invests in the security infrastructure described in this chapter simultaneously creates the enabling conditions for Zero-Copy Integration to be adopted with confidence, because it provides the technical assurance that governed, in-place data access is genuinely governed and genuinely monitored.
8.13 Summary and Architectural Imperatives
This chapter has examined the security architecture of the Zero-Copy enterprise from the foundational argument that data replication creates attack surface through to the specific mechanisms by which a Zero-Copy architecture implements security-by-design across its Data, Application Integration, and Event planes. The argument developed through the chapter may be summarised in six claims.
First, data replication is a security risk as well as an economic and governance risk. Every replica of sensitive data is a potential point of breach, and the proliferation of replicas that characterises conventional integration architectures creates an attack surface that is typically larger, more complex, and less consistently secured than the enterprise recognises. The Zero-Copy approach reduces this attack surface as a direct architectural consequence of its foundational principle.
Second, Zero Trust architecture and Zero-Copy Integration are expressions of the same underlying security philosophy applied to different architectural layers. The enterprise that frames its Zero-Copy investment as the data architecture dimension of its Zero Trust programme achieves better organisational alignment and more sustained commitment than one that treats them as separate initiatives.
Third, Zero-Copy Integration enables a security posture that is structurally superior to that of a replication-centric architecture: it enforces the principle of least privilege at the architectural level, concentrates data access through audited interfaces, simplifies breach investigation by limiting the scope of potential data exposure, and makes the enterprise’s data protection obligations easier to demonstrate to regulators.
Fourth, the security of the Zero-Copy architecture depends on the quality of the policies that govern data access, and those policies must be expressed as code — in OPA and Kyverno — rather than as documents, to ensure consistent, automatic, and auditable enforcement across the full enterprise environment.
Fifth, the identity federation challenge of the multi-cloud enterprise — creating a coherent, mutually trusted identity infrastructure from disparate identity providers — is a foundational requirement for the ABAC access control model and must be addressed before fine-grained, policy-mediated data access can be implemented reliably. SPIFFE workload identities and IBM Security Verify provide the technical components of this federation; their integration into a coherent enterprise identity architecture requires deliberate design and organisational commitment.
Sixth, the protection of data in use through confidential computing represents the completion of the encryption lifecycle for the most sensitive data assets, and should be considered by enterprises whose regulatory or commercial obligations require the highest assurance of data protection during processing — particularly in multi-cloud and co-hosted environments where the cloud provider’s physical access to processing infrastructure cannot be entirely excluded from the threat model.
Several architectural imperatives emerge from this analysis. The first is the establishment of a comprehensive data inventory as a prerequisite for the Zero-Copy security posture: the enterprise cannot reduce its attack surface without first understanding the full scope of the sensitive data locations it must address, and IBM Guardium’s data discovery capabilities provide the technical mechanism for this inventory. The second is the design of access control policies in OPA before the deployment of the federated access infrastructure that those policies govern: a federated data access architecture without mature, tested access control policies is a security liability, not a security improvement. The third is the adoption of mutual TLS and SPIFFE workload identities as default requirements for all service-to-service communication across the enterprise’s cloud environments, establishing the identity and encryption foundation on which all other security controls depend. The fourth is the integration of IBM QRadar with IBM Guardium and IBM Cloud Pak for Security to create the correlated, intelligence-enriched threat detection capability that transforms data activity monitoring from a compliance-oriented record-keeping function into an active security capability.
The chapter that follows extends the architectural framework to the integration fabric level, examining how the Data Plane, Application Integration Plane, and Event Plane described in this and preceding chapters are unified into a coherent enterprise integration capability whose governance, observability, and economic characteristics meet the strategic objectives that motivated the adoption of Zero-Copy Integration in the first place.
If you are finding this content useful, please consider supporting the author's efforts by purchasing a complete digital or hard-copy version.
Zero-Copy Integration: Architecture for the Fragmented Enterprise
© 2026 by Alan Hamilton
is licensed under CC BY-SA 4.0
![]()
![]()
![]()