Chapter 9 — Integration Fabrics: The New Digital Backbone
From Point-to-Point Pipelines to a Unified, Governed Fabric for API, Event, and Data Integration
The three preceding chapters of this part have examined, in turn, the technical planes that constitute a Zero-Copy Integration architecture: the Data Plane, through which analytical and operational workloads access persistent data assets in place; the Application Integration Plane, through which services communicate via governed, versioned API contracts; and the Event Plane, through which state changes are propagated as lightweight notifications rather than bulk data transfers. Each plane has been examined as a distinct architectural domain with its own principles, patterns, and platform capabilities. In practice, however, these planes do not operate independently. They form a coherent, interdependent integration architecture whose value to the enterprise depends not on the properties of each plane in isolation but on the consistency with which they are governed, the coherence with which they are operated, and the degree to which they are experienced by consuming teams as a single, unified capability rather than three separate integration systems to be navigated independently.
The concept that unifies these planes is the enterprise integration fabric. A fabric, in the architectural sense, is not merely a collection of integration technologies operating in proximity; it is a managed, governed, observable integration capability that treats API management, event streaming, and data access as complementary disciplines within a single operational and governance model. The fabric provides the common infrastructure through which integration capabilities are published, discovered, consumed, and monitored; the common governance framework through which access policies are defined, enforced, and audited; and the common operational tooling through which the health, performance, and cost of the enterprise’s integration capability are managed as a coherent whole.
The case for the integration fabric is fundamentally the same as the case for Zero-Copy Integration itself: without a unifying framework, the natural tendency of a large enterprise is towards fragmentation. Each business domain acquires its own integration tools; each project establishes its own point-to-point connections; each team manages its own API gateway, its own Kafka cluster, its own data extract pipeline. The result is an integration estate that mirrors the data replication problem described in earlier chapters: dispersed, inconsistently governed, operationally expensive to maintain, and increasingly difficult to secure and audit. The integration fabric addresses this fragmentation by establishing a platform-level capability that all domains share, whilst preserving the autonomy of individual domains to design and operate their own integration flows within the governance boundaries that the fabric enforces.
This chapter examines the enterprise integration fabric in depth. It begins by establishing a precise definition of what the fabric is and what distinguishes it from the point-to-point integration patterns that it supersedes. It then examines how the API, Event, and Data integration disciplines are unified within the fabric, and how that unification produces governance and operational benefits that no individual integration plane can deliver alone. It proceeds to examine IBM Cloud Pak for Integration as an enterprise-grade integration fabric implementation, alongside the open-source ecosystem of integration tools that complements and interoperates with it. It examines the emerging role of AI-assisted integration operations in managing the governance and performance of large-scale fabric deployments. The chapter concludes with a blueprint for designing a cross-cloud integration fabric, an examination of the relationship between the integration fabric and the data mesh organisational model, and a summary of the architectural imperatives that flow from the analysis.
9.1 What Is an Enterprise Integration Fabric?
The term integration fabric is used in the industry with a degree of looseness that can obscure its precise meaning. It is applied by vendors to products ranging from single-protocol message brokers to comprehensive multi-capability platforms, and by architects to architectures ranging from a common API gateway to a fully unified integration operating model. A precise definition is therefore essential before the concept can be used to drive architectural decision-making.
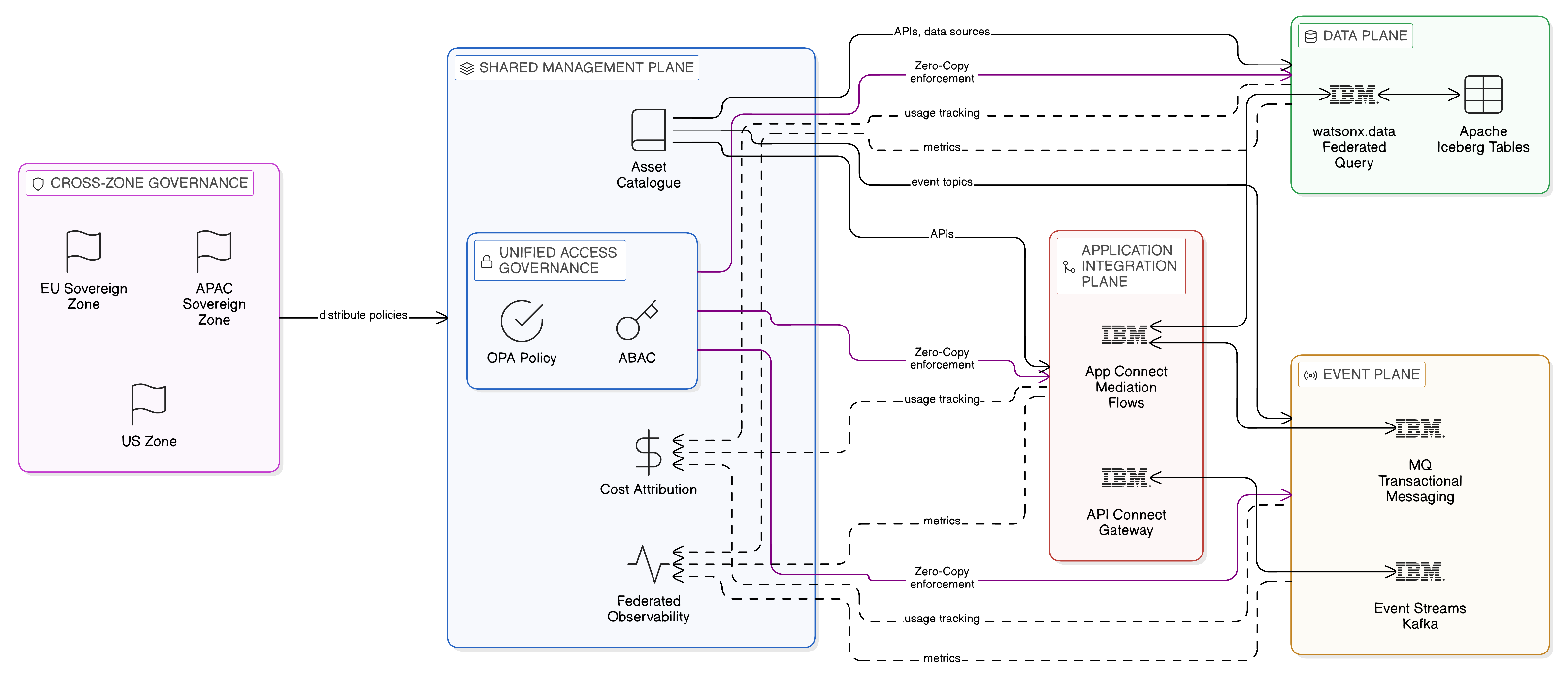
An enterprise integration fabric is a shared, governed integration platform that provides, within a single operational and governance model, the capabilities required to implement the full range of integration patterns that the enterprise requires: synchronous API-based integration, asynchronous event-driven integration, and federated data access. It provides these capabilities not as isolated products that happen to be operated by the same team but as integrated capabilities that share a common governance model — common cataloguing of integration assets, common access control policies, common operational monitoring, and common observability infrastructure — whilst remaining independently deployable and independently scalable.
Several characteristics distinguish a genuine integration fabric from a collection of integration products that falls short of the fabric model. The first is a shared asset catalogue: the fabric maintains a single inventory of all integration assets — APIs, event topics, data sources, integration flows — that is accessible to all teams that might consume or operate those assets. This catalogue is the discovery mechanism through which consuming teams find the integration capabilities they require and the governance mechanism through which the owners of those capabilities manage who may access them and on what terms. Without a shared catalogue, integration assets are opaque to teams outside the domain that created them, forcing each consuming team either to establish direct relationships with asset owners or to create their own copies of the data they require — precisely the replication sprawl that the Zero-Copy philosophy exists to eliminate.
The second distinguishing characteristic is unified access governance: the fabric enforces a consistent access control model across all integration asset types. The same policy framework that governs which consumers may invoke an API also governs which consumers may subscribe to an event topic or query a federated data source. This uniformity is significant because it means that the enterprise’s data governance obligations — its regulatory requirements to control access to personal data, commercially sensitive information, and regulated content — are enforced by a single, consistent mechanism rather than by separate, potentially inconsistent mechanisms in each integration plane. An enterprise that manages API governance separately from event topic governance and data access governance will, over time, develop inconsistencies between these governance regimes that create both compliance exposure and operational complexity.
The third distinguishing characteristic is shared operational observability: the fabric provides a single operational view of the health, performance, and utilisation of the entire integration capability, spanning API transactions, event throughput, and data query execution. This unified observability is essential for the operational management of a complex integration estate: without it, the operations team must correlate data from multiple disparate monitoring systems to understand the end-to-end behaviour of an integration flow that traverses multiple planes of the architecture. With it, the operations team can observe the complete integration lifecycle — from the API request that initiates a business transaction through the event publication that communicates its completion to the data query that provides the analytical context — within a single operational console, correlated by the transaction identifier that the fabric propagates through all interactions.
The fourth distinguishing characteristic, and the one most directly relevant to the Zero-Copy philosophy, is governance-enforced data flow control: the fabric is designed to make the movement of data visible, auditable, and subject to policy enforcement at every point in the integration lifecycle. Where conventional integration tooling allows data to flow freely between systems through whatever mechanisms the developers of those systems find convenient, the integration fabric enforces the discipline that data flows only through governed channels, that those channels are catalogued and monitored, and that any flow that crosses a jurisdictional boundary or involves regulated data types is subject to the additional governance controls that the applicable regulatory framework requires.
It is important to distinguish the enterprise integration fabric, as described here, from the older concept of the Enterprise Service Bus. The ESB was a centralised integration platform through which all inter-application communication was routed, creating a single point of control but also a single point of failure, a performance bottleneck, and an operational dependency that ultimately proved incompatible with the scale and pace of modern enterprise integration. The integration fabric is explicitly decentralised: it provides shared governance, catalogue, and observability capabilities whilst distributing the execution of integration flows across multiple runtime environments, each deployed within the sovereign zone or cloud region where its integrations operate. The fabric is a governance and management model, not a runtime hub. This distinction is architecturally critical: an integration fabric that routes all traffic through a central execution environment is not a fabric but an ESB rebranded, and it will reproduce the scaling, resilience, and sovereignty liabilities of its predecessor.
9.2 Unifying API, Event, and Data Integration
The three integration disciplines described in preceding chapters — API-based application integration, event-driven integration, and federated data access — address distinct integration requirements and employ distinct technical mechanisms. The enterprise integration fabric does not collapse these distinctions: it does not, and should not, attempt to use a single technical mechanism for all integration requirements. Rather, it unifies them at the governance and operational level, providing a common management plane above the technically distinct runtime planes that each discipline requires.
Understanding why this unification matters, and what it achieves, requires examining the specific governance challenges that arise when the three disciplines operate independently. Consider a scenario in which a consuming application team requires access to customer data for a new digital service. In an enterprise without an integration fabric, the team must navigate three separate systems: an API management portal to discover and request access to the customer API; a separate event management console to subscribe to the customer event topics they require for real-time notifications; and a separate data catalogue to identify and request access to the customer data assets they need for their analytics. Each of these systems has its own access request process, its own approval workflow, and its own governance model. The consuming team experiences the enterprise’s integration capability as three separate, uncoordinated bureaucracies rather than as a single, coherent service. The duplication of process, the inconsistency of governance standards, and the friction of navigating multiple systems combines to produce precisely the kind of consuming-team frustration that drives shadow integration: the creation of private copies of data and informal point-to-point connections that bypass the governed integration infrastructure entirely.
The operational consequences of ungoverned integration fragmentation are equally significant. If an incident arises in which a consuming application is behaving unexpectedly — showing stale customer data, or failing to process customer events correctly — the operations team investigating the incident must correlate information from three separate monitoring systems: the API management platform’s request logs, the event streaming platform’s consumer lag metrics, and the data access platform’s query logs. Without a unified view, the investigation is slow, error-prone, and dependent on the operational knowledge of the specific individuals who are familiar with each of the three separate systems. In regulated industries where incident response times are scrutinised by supervisory authorities, this fragmentation of operational visibility carries direct compliance risk.
The integration fabric addresses both of these problems through the common management plane. From the consuming team’s perspective, the fabric presents a single integration portal through which all integration assets — APIs, event topics, and data sources — are discoverable and accessible. A team that requires access to customer data in all three forms submits a single access request through the fabric portal, which routes the request to the appropriate governance owners and, once approved, provisions access to the relevant API endpoints, event topic subscriptions, and data source access rights simultaneously. The consuming team’s integration experience is unified; the governance of that integration is consistent; and the audit trail of the access grant is coherent across all three integration disciplines.
From the operational perspective, the fabric’s unified observability plane correlates events across all three integration planes into a single operational view. An incident that manifests as stale customer data in the consuming application can be investigated through a single operations console that shows the API request timeline, the event consumer lag, and the data query execution history in a correlated, time-ordered view. The operations team can identify, without switching between systems, whether the staleness originates in the API plane — a slow or failing upstream service — the event plane — a consumer group that has fallen behind the event log — or the data plane — a query that is returning cached results beyond its intended refresh interval. This diagnostic clarity, achievable only through unified observability, is not a convenience; in complex integration architectures, it is the difference between resolving an incident within minutes and spending hours correlating data from disparate systems.
The unification of API, Event, and Data integration within the fabric also has specific implications for Zero-Copy architecture enforcement. The fabric’s governance model can be designed to make the creation of unnecessary data copies difficult or impossible within the governed integration estate. An API that returns a large dataset can be governed by a policy that prevents bulk data downloads through the API gateway, enforcing pagination and cursor-based access patterns that limit the volume of data any single consumer can extract in a given time window. An event topic can be governed by a policy that restricts the retention of event content in consumer-side databases, requiring consuming systems to access persistent data through the fabric’s data access plane rather than accumulating a replica from the event stream. A data source can be governed by a policy that prevents full-table scans and requires all queries to include filters that limit the scope of data returned. Together, these fabric-level policies constitute an architectural enforcement of Zero-Copy discipline that operates above the level of individual integration flows, creating systematic constraints against replication rather than relying on the judgement of individual development teams who may not have the sovereign and economic context to make consistently correct decisions.
9.3 IBM Cloud Pak for Integration as a Unified Fabric
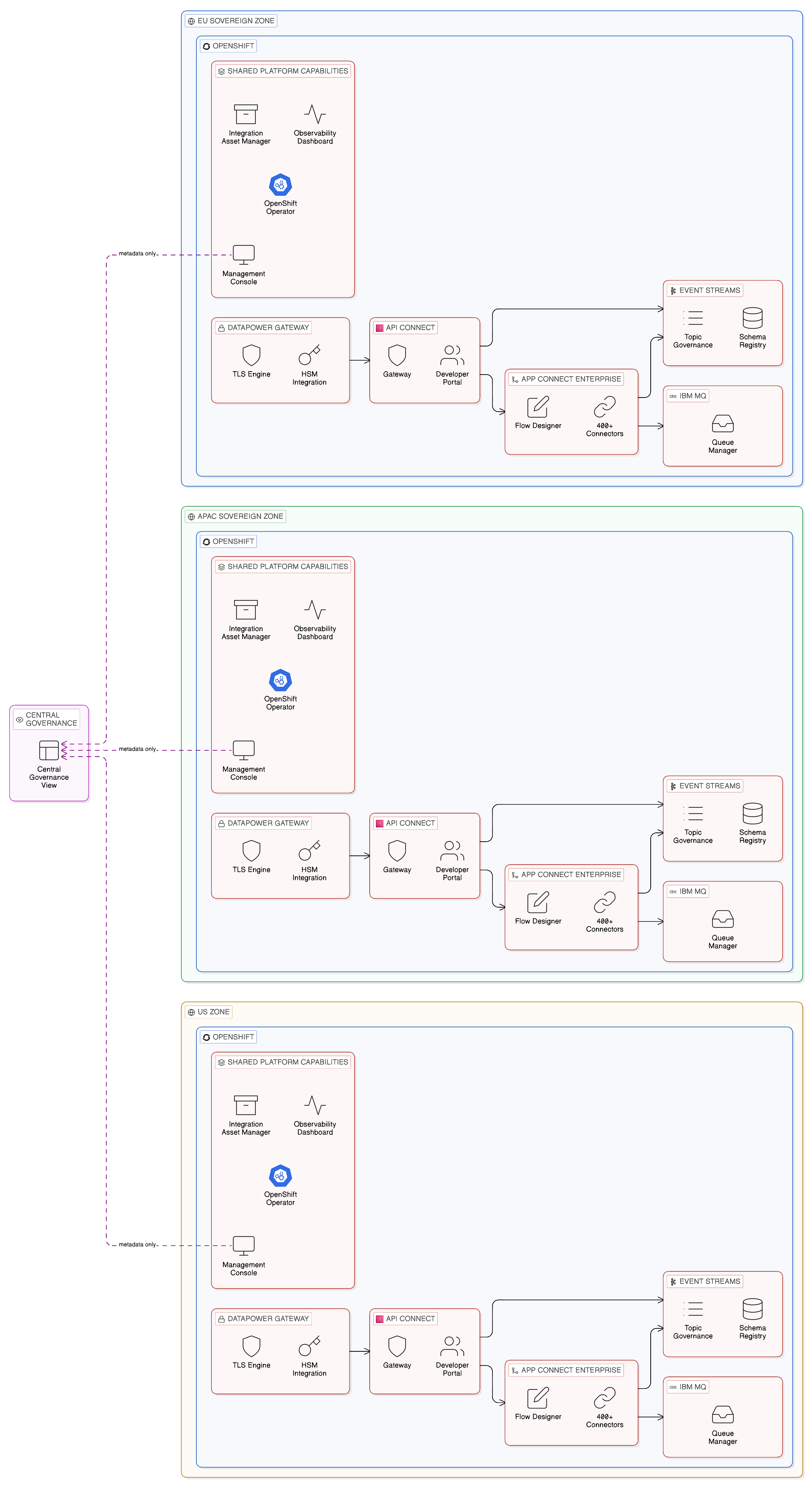
IBM Cloud Pak for Integration is IBM’s enterprise integration platform, designed from its inception to provide the unified, multi-capability integration fabric described in the preceding section. It packages, within a single deployed platform running on Red Hat OpenShift, the full set of integration capabilities that the enterprise integration fabric requires: API management, event streaming, application integration mediation, secure gateway, and high-speed data transfer — together with the shared management, governance, and operational capabilities that transform these individual products into a coherent fabric.
The constituent capabilities of IBM Cloud Pak for Integration reflect the full breadth of the enterprise integration requirement. IBM API Connect provides the lifecycle management of APIs from design through publication, subscription, and retirement, together with the gateway enforcement of API access policies and the developer portal through which consuming teams discover and subscribe to APIs. IBM Event Streams, the platform’s Apache Kafka-based event streaming component, provides the high-throughput, durable event backbone described in Chapter 7, together with the schema registry and event topic governance that the enterprise event catalogue requires. IBM App Connect Enterprise provides the visual integration flow design capability, the library of pre-built connectors, and the runtime execution environment for integration flows that connect applications, transform data, and orchestrate business processes across the full range of enterprise systems and protocols. IBM DataPower Gateway provides the enterprise-grade security gateway for API traffic, with hardware security module integration, XML threat protection, and the high-performance TLS termination that high-volume API environments require. IBM MQ provides the transactional messaging layer, ensuring exactly-once, ordered delivery for the class of integration requirement — payment instructions, reservation confirmations, legally binding notifications — that demands guarantees beyond those of at-least-once event streaming.
What distinguishes Cloud Pak for Integration as an integration fabric, rather than merely a collection of integration products, is the set of shared capabilities that span all of these individual components. The platform provides a single management console through which all integration assets — APIs, event topics, integration flows, message queues, and data connections — are managed and monitored within a unified operational view. It provides a shared asset catalogue, implemented through the platform’s integration asset manager, through which integration assets are published, documented, and made discoverable to consuming teams. It provides a unified operational dashboard that correlates metrics from all integration components into a single health and performance view. And it provides a common deployment model, based on Red Hat OpenShift operators, through which all platform components are deployed, configured, upgraded, and scaled through a consistent Kubernetes-native operational discipline. This common deployment model is not merely an operational convenience; it ensures that the governance configuration, security controls, and observability instrumentation of each component are managed through the same operational process, eliminating the category of governance gap that arises when different integration products are deployed and operated by different teams using different tooling.
The deployment of Cloud Pak for Integration on Red Hat OpenShift is architecturally significant in the context of this book’s central themes. OpenShift’s support for deployment across on-premises infrastructure, private cloud, and public cloud platforms means that Cloud Pak for Integration can be deployed within specific sovereign zones, with all integration capabilities operating locally within the zone rather than depending on connectivity to a remote cloud-hosted platform. An enterprise with sovereign zone requirements in Europe, Asia-Pacific, and North America can deploy a Cloud Pak for Integration instance within each zone, each enforcing the integration policies and access controls applicable to that zone, with the shared management plane providing a central governance view across all zonal instances without requiring any sensitive operational data to leave the zone in which it was generated. This is the practical realisation of the distributed execution, centralised governance model that the integration fabric concept requires and that the ESB model could not deliver.
The platform’s relationship to the Zero-Copy philosophy operates at multiple levels. At the most immediate level, Cloud Pak for Integration provides the implementation foundation for the API-based and event-driven integration patterns described in Chapters 6 and 7, enabling the enterprise to replace data-replication-based integration with API and event-based alternatives. At a deeper level, the platform’s shared governance capabilities enforce the Zero-Copy discipline across the integration estate, making it operationally difficult for development teams to create integration patterns that involve unnecessary data movement without those patterns being visible to and approvable by the enterprise’s governance function. At the deepest level, the platform’s deployment model supports the distributed, sovereign-zone-aware topology that Zero-Copy Integration requires, ensuring that integration capabilities are available locally within each sovereign zone and do not create the cross-boundary data dependencies that would compromise the enterprise’s jurisdictional controls.
IBM’s ongoing evolution of Cloud Pak for Integration reflects the changing requirements of the enterprise integration landscape. The platform has progressively expanded its support for cloud-native deployment patterns, event-driven integration capabilities, and AI-powered integration automation. IBM’s investment in the AI-assisted integration design and anomaly detection capabilities of the platform reflects the recognition that the operational complexity of a large integration fabric — hundreds of APIs, thousands of event topics, dozens of integration flows — exceeds the capacity of manual operational management, and that AI-powered tooling is essential to maintain the operational discipline and governance quality that a fabric of this scale requires. This theme is examined further in Section 9.5.
9.4 The Open-Source Integration Ecosystem
An honest account of the enterprise integration landscape must acknowledge that IBM Cloud Pak for Integration does not exist in isolation. It is one implementation of the integration fabric concept within a rich ecosystem of open-source integration tools, many of which are used by enterprises either as alternatives to commercial platforms or as complements to them. Understanding this ecosystem is important for the technology leader both because it informs the strategic choice of integration platform and because the open-source projects that constitute it provide the technical foundations on which commercial platforms — including IBM’s — are built.
Apache Camel is the most widely used open-source integration framework for Java-based enterprise environments. It provides an extensive library of integration components — several hundred connectors for enterprise systems, protocols, and data formats — together with a domain-specific language for defining integration routes that transform, filter, and route messages between systems. Camel’s strength lies in its breadth of connectivity: it can connect to virtually any enterprise system or protocol that a development team is likely to encounter, from modern REST APIs and Kafka topics to legacy COBOL file formats and AS/2 EDI exchanges. Its deployment flexibility is comparable, running as a standalone Java application, within a Spring Boot or Quarkus container, on Kubernetes, or as a component within a larger integration platform. Red Hat Camel, IBM’s parent company Red Hat’s supported distribution of Apache Camel, provides the enterprise support, certification, and lifecycle management that production deployments of Camel in regulated industries require. The significance of this relationship is that the open-source Camel project and IBM’s broader integration portfolio are not in competition but in alignment: IBM App Connect Enterprise includes Camel-based connectivity in some of its connector implementations, and Red Hat Camel provides a supported path to Camel-based integration for enterprises that prefer to build integration flows directly in Camel rather than through a visual integration designer. The choice between these approaches is not a vendor choice but an engineering model choice, and enterprises with mature Java integration capability may find Red Hat Camel the more natural complement to their existing development practices.
Kong is the most widely adopted open-source API gateway, providing a high-performance, extensible gateway for REST API traffic with a rich plugin ecosystem that covers authentication, rate limiting, request transformation, logging, and observability. Kong Gateway’s open-source edition is suitable for development and smaller production deployments; Kong Konnect, its commercial offering, provides the centralised management, analytics, and enterprise support features required for large-scale production governance. For enterprises whose API governance requirements do not demand the full breadth of IBM API Connect’s lifecycle management capabilities, Kong provides a viable and widely supported alternative. For enterprises using Cloud Pak for Integration, Kong can operate at the edge of the API estate — managing external partner APIs, consumer-facing mobile APIs, or developer ecosystem APIs — whilst IBM API Connect manages the core integration APIs that underpin the enterprise’s internal integration flows. This layered gateway architecture, combining a high-performance edge gateway with a full lifecycle management platform at the core, is a common pattern in enterprises with diverse API estates and varied consumer populations.
Two further platforms occupy significant positions in the enterprise integration landscape and deserve explicit consideration within the Zero-Copy framework: StreamSets and webMethods. Neither is a pure open-source project, but both have open-source foundations and both are present in a large number of enterprise integration estates, frequently as pre-existing investments that a Zero-Copy transformation programme must accommodate rather than replace.
StreamSets, now part of the StreamSets DataOps Platform, is most precisely characterised as a governed data movement and change data capture orchestration layer. In the Zero-Copy architecture, its primary role is in the situations where controlled, justified data movement is unavoidable — and the book has been explicit throughout that Zero-Copy is a discipline and an objective rather than a categorical prohibition on all data transfer. StreamSets excels at CDC-based pipeline management: it captures change events from source systems that do not expose a native event streaming interface — older relational databases, mainframes with limited API capability, proprietary packaged applications — and delivers those change events to IBM Event Streams or other Kafka-compatible brokers as the first step of the event-driven architecture. In this role it acts as a governed CDC bridge, handling schema drift automatically, versioning pipeline configurations, and providing the audit trail of what was captured and when. Its DataOps lineage capability records the full provenance of every pipeline execution — source system, transformations applied, destination, volume, timestamp — in a format that can be published via OpenLineage to IBM Knowledge Catalog, making it directly compatible with the governance framework described in Chapter 11. For enterprises that are migrating from a copy-heavy Stage One estate and need to bring historical ETL pipelines under governance visibility before replacing them with event-driven or federated access patterns, StreamSets provides a pragmatic transitional path: catalogue and govern the existing pipelines first through their lineage output, then progressively replace them as the maturity model advances. Its pipeline portability — the same pipeline definition deployable across cloud providers, on-premises infrastructure, and edge locations — also aligns with the sovereign zone deployment model: StreamSets engines can be deployed within each sovereign zone under IBM Cloud Satellite management, ensuring that even controlled data movement remains localised and governed. The honest caveat is that StreamSets is fundamentally a data movement tool, and its governance capabilities must not be used as justification for data movement that the Zero-Copy principles would argue against. It belongs in the architecture as a governed exception handler for migration and legacy connectivity scenarios, not as the default integration pattern for new integration flows.
webMethods, now offered as webMethods.io in its cloud-native form within the Software AG — now IBM — portfolio, is principally an application integration and API management platform, occupying a position functionally adjacent to IBM App Connect Enterprise and IBM API Connect. Its relevance to the Zero-Copy fabric architecture is primarily in two scenarios. The first is the heterogeneous estate scenario: an enterprise with a significant existing investment in webMethods integration flows and webMethods API Gateway does not need to replace those assets in order to participate in the Zero-Copy governance model. The webMethods API Gateway can be brought under the same governance umbrella as IBM API Connect through the integration fabric’s OpenAPI standard-based policy framework — API contracts published through webMethods Gateway can be registered in IBM Knowledge Catalog alongside APIs governed by IBM API Connect, and OPA policies enforcing data classification and jurisdiction-aware routing can be applied at both gateways consistently. This heterogeneous gateway governance model is not a second-class alternative to a single-vendor deployment; it is the practical reality of most enterprise integration estates, and the Zero-Copy architecture’s standard-based governance model is designed to accommodate it. The second scenario is the B2B and partner integration dimension, where webMethods has historically had significant strength in EDI, AS2, and partner gateway integration — the complex, standards-governed partner connectivity that financial services, healthcare, and manufacturing enterprises depend upon. In a Zero-Copy architecture, partner-facing B2B integration is a natural governance boundary: data flowing to or from external partners crosses the enterprise boundary and is therefore among the highest-priority integration flows to bring under governance controls. webMethods’ B2B capability, governed through its API Gateway with lineage published to IBM Knowledge Catalog, provides the partner connectivity layer for the Zero-Copy enterprise without requiring the replacement of a mature, certified B2B infrastructure.
Apache Kafka, as described in Chapter 7, is the de facto open-source standard for enterprise event streaming. Its relevance to the discussion of open-source integration fabrics is that it serves as the common event backbone that multiple commercial and open-source integration platforms interoperate with. Both IBM Event Streams and the open-source Kafka project speak the same Kafka protocol; a producer that publishes events to an IBM Event Streams topic and a producer that publishes events to an open-source Kafka cluster are interchangeable from the consumer’s perspective. This protocol compatibility means that the event streaming layer of an enterprise integration fabric can be built from a combination of IBM Event Streams instances — in environments where enterprise support and OpenShift-native deployment are required — and open-source Kafka clusters — in environments where operational simplicity and cost are the primary considerations — without compromising the interoperability of the fabric.
The Cloud Native Computing Foundation’s landscape of projects provides a comprehensive reference for the open-source capabilities that underpin the infrastructure on which both commercial and open-source integration platforms run. Kubernetes is the deployment substrate for all cloud-native integration components, providing the orchestration, scaling, and lifecycle management that production integration deployments require. Prometheus and Grafana provide the metrics collection and visualisation infrastructure for integration observability. OpenTelemetry, the CNCF’s distributed tracing and observability standard, provides the instrumentation framework through which integration platforms expose their operational telemetry in a standardised, vendor-neutral format that can be consumed by any compatible monitoring backend. Envoy, the high-performance proxy that underlies Istio and OpenShift Service Mesh, provides the data plane for service-to-service communication governance within the integration fabric. The enterprise architect who understands these foundational open-source capabilities is better positioned to evaluate commercial platforms that build upon them, to identify where commercial value-add genuinely exceeds the capabilities of the open-source foundation, and to make informed build-versus-buy decisions for each layer of the integration estate.
The strategic stance of the technology leader with respect to the open-source integration ecosystem should be one of informed selectivity rather than either wholesale adoption or wholesale rejection. Open-source integration tools provide genuine capabilities — breadth of connectivity in the case of Apache Camel, performance and extensibility in the case of Kong, ubiquity and ecosystem breadth in the case of Apache Kafka — that justify their adoption in specific contexts. They also carry responsibilities — for operational support, security patching, upgrade management, and the resolution of production incidents — that must be met either by the enterprise’s own engineering capability or through the purchase of supported distributions from vendors such as Red Hat. The integration fabric should leverage open-source capabilities where they represent the strongest technical choice, and should apply commercial platforms where the enterprise support, governance integration, and lifecycle management that commercial products provide add sufficient value to justify their cost. Neither ideology serves the enterprise well; only disciplined, context-specific evaluation of technical and operational requirements produces integration estates that are simultaneously capable, governable, and economically sustainable.
9.5 AI-Assisted Integration Operations
The operational management of an enterprise integration fabric at scale presents challenges that exceed the practical capacity of manual management processes. An estate of several hundred APIs, each with its own versioning lifecycle, consumer base, and performance characteristics; several thousand event topics, each with its own schema evolution history and consumer group configuration; and dozens of integration flows, each connecting multiple systems across sovereign zone boundaries — the aggregate management burden of an estate of this complexity cannot be addressed adequately by a team operating with traditional monitoring dashboards and manual escalation procedures. Two distinct failures result from the attempt: either the team is overwhelmed and governance quality degrades, allowing the fragmentation and replication patterns that the fabric was designed to prevent to re-emerge; or the team is so large that its cost erodes the economic benefit that the integration fabric was established to deliver.
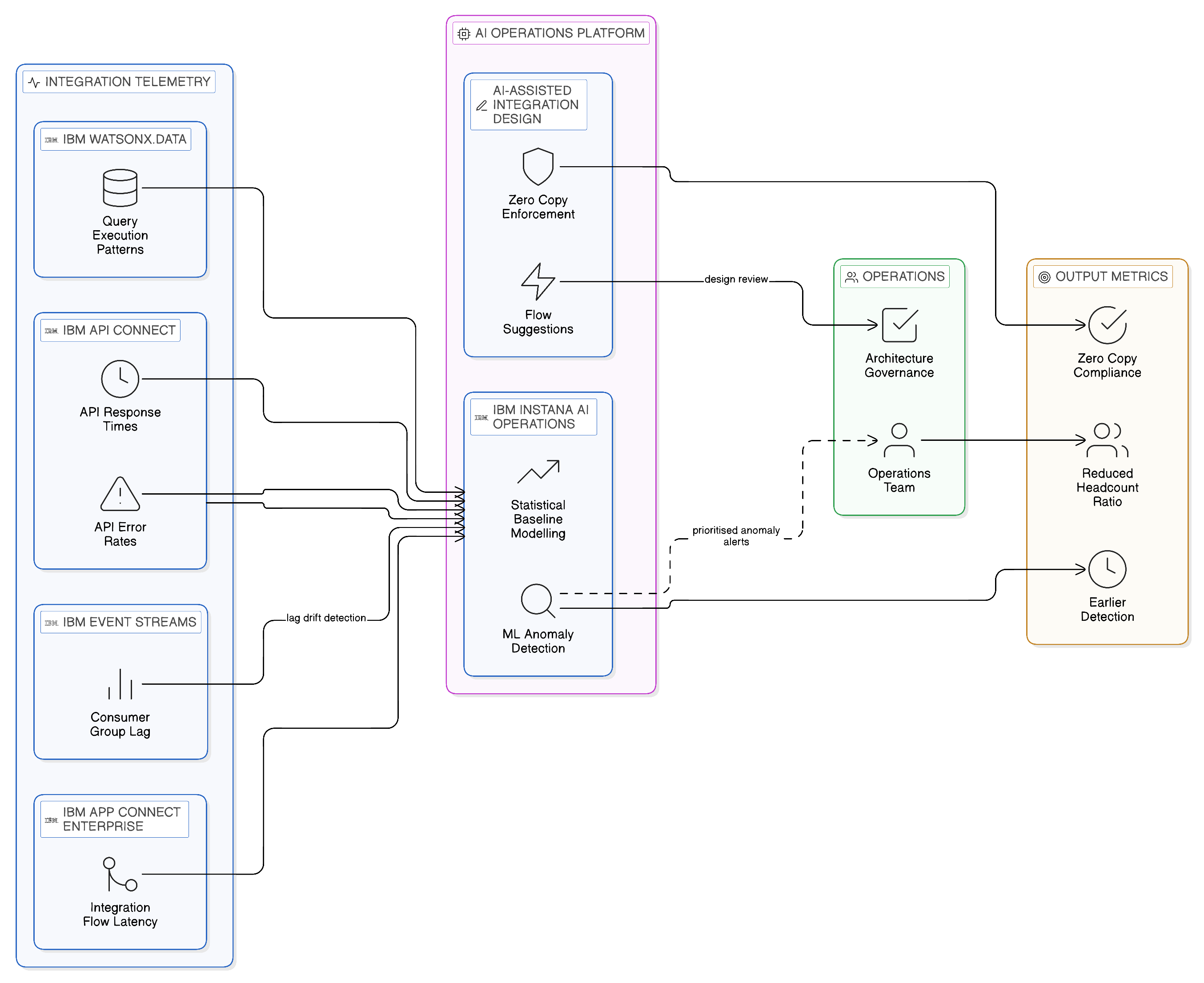
The resolution of this tension is AI-assisted integration operations: the application of machine learning, anomaly detection, and generative AI capabilities to the management of the integration fabric, enabling a smaller team to govern and operate an estate of greater complexity than would otherwise be feasible.
IBM Instana, IBM’s application performance monitoring platform, provides the AI-powered anomaly detection capability that is most immediately relevant to integration fabric operations. It applies statistical baseline modelling and machine learning to integration telemetry — API response times, event consumer lag, data query execution patterns, error rates — to identify deviations from normal behaviour that may indicate emerging performance degradation, configuration drift, or security-relevant access anomalies. This capability is particularly valuable because the most operationally significant problems in large integration estates are characterised not by sudden, threshold-crossing events but by gradual degradation: an integration flow whose response time increases incrementally over weeks, a consumer group whose lag grows slowly across a month of increasing event volume, an API whose error rate creeps upward as an upstream dependency begins to struggle under load. These patterns will not trigger any individual threshold alert but are readily detectable by the AI-powered baseline models that IBM Instana maintains for each integration component. The operations team receives an alert whilst there is still time to investigate and remediate — before the gradual degradation crosses the threshold of operational impact.
IBM’s integration platform has also introduced AI-assisted integration design capabilities that accelerate the creation of integration flows, the mapping of data schemas, and the selection of appropriate integration patterns for a given requirement. Experienced integration architects can describe a business integration requirement and receive a suggested integration flow that they can review, modify, and deploy rather than constructing from scratch. Less experienced developers can create correct-by-construction integration flows that conform to the enterprise’s architectural standards without requiring deep expertise in every integration technology the fabric supports. The quality and governance implications of these AI-generated designs are worth examining with care: a generative system that produces integration designs that do not conform to Zero-Copy principles — that suggest, for example, creating a database replica where a federated query would serve the requirement — would undermine the Zero-Copy discipline rather than reinforce it. IBM’s AI-assisted integration capabilities, deployed within the governance context of Cloud Pak for Integration and its associated policy frameworks, are designed to operate within the governance boundaries that the enterprise has established, defaulting to federated access and event-driven patterns rather than replication-based alternatives. This alignment between AI-generated designs and architectural governance principles is not incidental; it is a design requirement that must be explicitly validated before AI-assisted design tools are deployed into a Zero-Copy integration estate.
For the technology leader, the practical implication of AI-assisted integration operations is a significant improvement in the ratio of integration complexity to operational headcount: an integration fabric that would previously have required a large team of specialist operators to manage reliably can, with AI-assisted monitoring and design tooling, be operated by a smaller team with a broader range of responsibilities. This does not diminish the importance of integration expertise; it changes its application, from routine monitoring and incident response to the higher-order activities of architecture governance, fabric evolution, and the continuous improvement of the AI systems themselves. The integration fabric, governed with AI assistance and operated by a smaller but more highly skilled team, becomes a more capable and more economically sustainable strategic asset than the manually operated integration estate it replaces.
9.6 Blueprint: Designing a Cross-Cloud Integration Fabric
The principles and capabilities described in the preceding sections of this chapter are brought together in a practical architectural blueprint for a cross-cloud integration fabric that is consistent with the sovereignty, resilience, and Zero-Copy disciplines that this book advocates. The blueprint describes the structural elements of such a fabric, the relationships between those elements, and the design principles that govern their configuration and operation. It is intended as a reference architecture rather than a prescriptive implementation guide: the specific choices of technology, deployment topology, and governance configuration will vary with the enterprise’s existing infrastructure, regulatory context, and organisational model.
9.6.1 Structural Elements of the Fabric
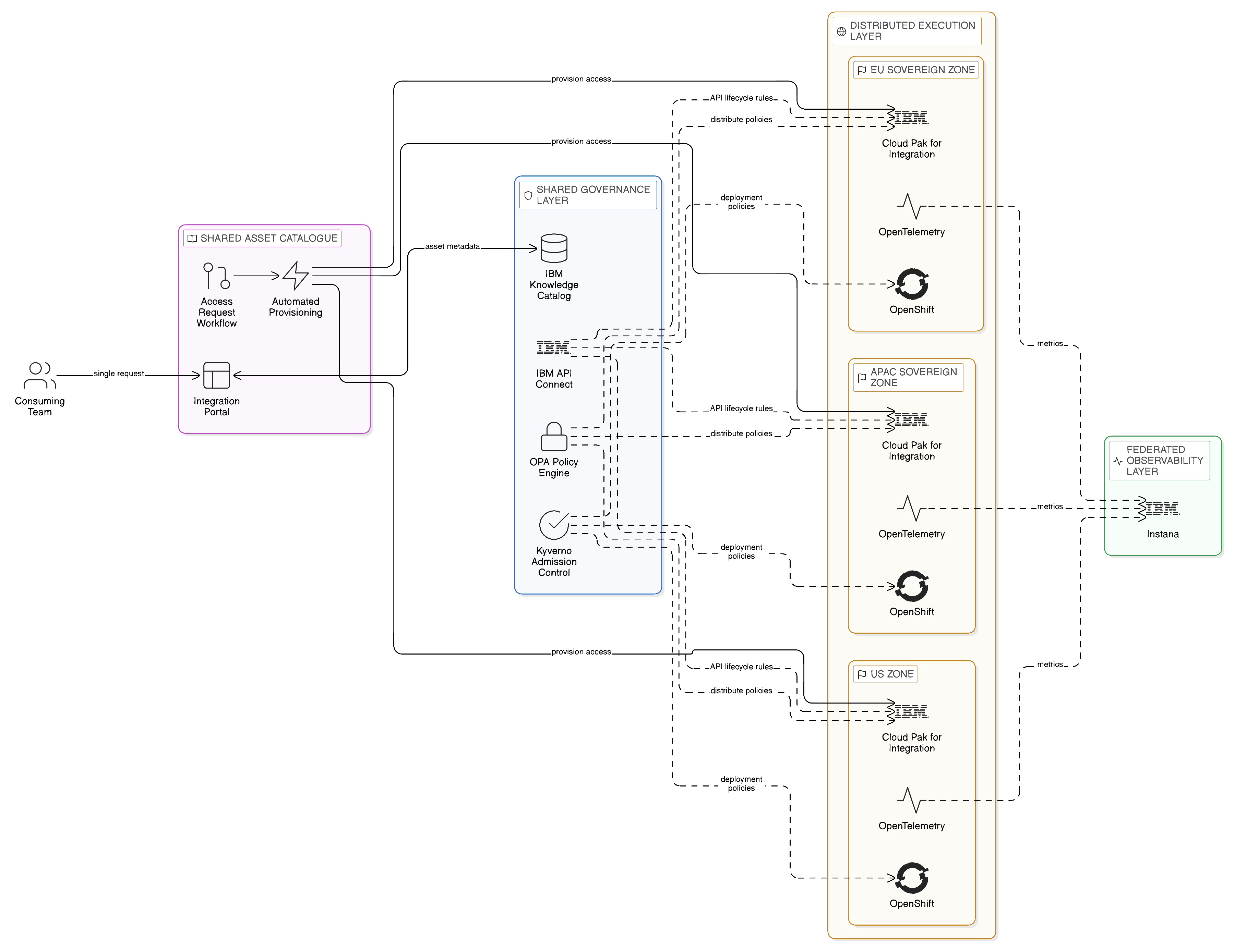
The cross-cloud integration fabric is composed of four structural elements: a distributed execution layer, a shared governance layer, a federated observability layer, and a shared asset catalogue. Each element plays a distinct role in the fabric architecture, and each must be designed with the sovereignty and resilience requirements of the enterprise in mind.
The distributed execution layer comprises the runtime instances of the integration components — API gateways, event streaming brokers, integration flow engines, and data virtualisation engines — that execute integration transactions within each sovereign zone. These instances are deployed locally within each zone, on OpenShift clusters that are themselves located within the zone’s physical infrastructure boundaries. They do not rely on connectivity to a central execution platform for normal operation; each zonal instance is capable of processing its integration workload independently of other zones, providing the operational autonomy and resilience that the multi-cloud, sovereign enterprise requires. IBM Cloud Pak for Integration’s OpenShift-native deployment model supports this distributed execution topology directly, with each zonal instance managed by the same operator-based deployment mechanism regardless of whether the underlying OpenShift cluster is on-premises or cloud-hosted. The operational consistency this model provides is a significant advantage over heterogeneous integration deployments: a Frankfurt data centre instance, a Singapore public cloud instance, and a São Paulo private cloud instance are all deployed and operated through the same tooling, with the same governance model, reducing the per-zone operational expertise burden that heterogeneous deployments impose.
The shared governance layer is the management plane of the fabric: the central capability through which integration asset policies are defined, the integration catalogue is maintained, and the cross-zone governance rules that govern which assets may be consumed by which zones and under what conditions are enforced. The shared governance layer does not execute integration transactions; it defines and enforces the policies under which the distributed execution layer operates. Critically, the shared governance layer must itself be designed with sovereignty in mind: the governance metadata it manages — the policy definitions, the access control records, the audit logs — may be subject to the same regulatory constraints as the operational data that the governed integration assets handle. The governance layer must therefore be deployable within the enterprise’s primary sovereign zone, with access provided to zone-specific governance administrators through the platform’s role-based access model rather than through a cloud-hosted shared service over which the enterprise has limited jurisdictional control.
The federated observability layer provides the operational visibility of the fabric across all zones without centralising the raw operational data that observability generates. Log data generated by integration operations within a sovereign zone may itself be subject to regulatory constraints, making the export of raw logs to a centralised observability platform a potential jurisdictional violation. The federated observability layer addresses this through a pattern of local aggregation and selective export: local observability agents collect and retain raw telemetry within each zone, whilst exposing aggregated, anonymised operational metrics to the central operations team without exporting raw telemetry. OpenTelemetry’s support for configurable export pipelines, combined with IBM Instana’s federated monitoring model, provides the technical foundation for this federated observability architecture. The result is a central operations team that can monitor the health and performance of the full fabric without requiring cross-boundary export of potentially regulated operational data.
The shared asset catalogue is the discovery and governance registry through which all integration assets are published and made accessible to consuming teams. It provides the unified interface through which a developer can search for and request access to APIs, event topics, and data sources without knowing in advance which team owns each asset or which zone it is operated from. The catalogue records the metadata of each asset — its schema, its access policies, its operational status, and its lineage within the integration architecture — and provides the workflow through which access requests are submitted, approved, and provisioned. IBM API Connect’s developer portal, combined with IBM’s integration asset management capabilities, provides the implementation foundation for this shared catalogue; open-source alternatives such as Backstage, the developer portal framework contributed to the CNCF by Spotify, provide a viable complement for enterprises that require a broader scope of asset cataloguing beyond API and event assets.
9.6.2 Design Principles for the Cross-Cloud Fabric
Several design principles govern the configuration of the cross-cloud integration fabric and distinguish a well-designed fabric from one that recreates, in integration infrastructure, the governance and resilience problems that the Zero-Copy philosophy exists to resolve.
The first principle is local execution by default. Every integration transaction should be executed as close as possible to the data that it accesses and the consumers that it serves. Integration flow engines should be deployed within the sovereign zones where their source and target systems reside; API gateways should be deployed within the zones where their consumer populations are located; event streaming brokers should be co-located with the producers and consumers they serve. Cross-zone integration traffic — the routing of an API request from a gateway in one zone to a service in another, or the mirroring of an event topic from one zone’s broker to another’s — should be the exception, governed by explicit policy, rather than the norm. This principle is not merely about performance optimisation; it is about ensuring that the integration architecture does not inadvertently create the cross-boundary data flows that the sovereignty framework prohibits.
The second principle is policy-as-code governance. All access control policies, cross-boundary routing rules, and data handling constraints should be expressed in machine-readable policy code — OPA policies, Kyverno admission policies, or equivalent — rather than in manually applied configurations or procedural guidelines. Policy-as-code ensures that governance is enforced consistently and automatically across all instances of the fabric, regardless of who deployed or configured those instances, and provides the version-controlled, auditable policy history that regulatory compliance demands. A policy estate that is expressed in documents rather than code is a policy estate that is enforced inconsistently, because it depends on human operators to correctly interpret and apply the relevant policies at each decision point.
The third principle is contract-first asset design. Every integration asset exposed through the fabric — every API, every event topic, every data source — should be defined by a published, versioned contract before its implementation is built. This contract-first discipline extends to event schemas — defined using AsyncAPI or Apache Avro with a schema registry — and to data source contracts — defined using data product specifications that describe the schema, quality, freshness, and access terms of the data source. Contract-first design ensures that the integration fabric’s catalogue contains accurate, authoritative asset descriptions that consuming teams can rely upon, and that changes to integration assets are managed through a governance process rather than deployed unilaterally in ways that break consuming systems.
The fourth principle is resilience by partition, not by replication. The resilience of the integration fabric should be designed to tolerate the failure of individual zones and the interruption of cross-zone connectivity without requiring the replication of integration state or data across zones as a prerequisite for recovery. API gateways should be designed to degrade gracefully to local capabilities when cross-zone routing is unavailable, rather than failing completely. Event streaming brokers should provide local durability for producers that cannot reach their designated broker, buffering events locally until connectivity is restored. Integration flows should be designed to operate in a local-first mode during connectivity disruptions, completing local processing and deferring cross-zone operations until the fabric is restored to full connectivity. This resilience model is consistent with the Zero-Copy philosophy: it achieves operational continuity through architectural design rather than through the data replication that would compromise the enterprise’s sovereignty posture.
The fifth principle is measurable, attributable integration economics. The integration fabric should expose the cost of integration — the compute, network, and storage costs associated with each integration asset and each integration flow — in a form that is attributable to the business domains that own and consume those assets. This cost attribution is the foundation of the FinOps discipline applied to integration: it makes the economic consequences of integration design decisions visible to the teams that make those decisions, creating the incentive structure that drives the adoption of Zero-Copy patterns over replication-based alternatives. An integration flow that moves a terabyte of data nightly from one system to another should have a visible cost that the owning business domain bears; an equivalent integration flow that subscribes to the relevant event topics and accesses data in place should have a demonstrably lower cost that the same domain benefits from. Without this cost visibility, the economic argument for Zero-Copy Integration remains abstract; with it, the argument is concrete, self-reinforcing, and embedded in the governance processes through which domain owners make integration design decisions.
9.6.3 The Fabric in Operation: A Worked Example
To make the blueprint concrete, it is instructive to trace the operation of the cross-cloud integration fabric through a representative integration scenario: the integration of a new digital retail channel with the enterprise’s core customer, order, and inventory management systems across a European sovereign zone and an Asian operational zone.
The digital retail channel team begins by searching the integration fabric’s shared asset catalogue for the integration assets they require. They find the Customer API, which exposes customer profile and preference data through a versioned REST interface governed by IBM API Connect; the Order Event Topic, which publishes order creation and status update events through IBM Event Streams; and the Inventory Data Source, which provides real-time inventory availability data through the federated query interface of IBM watsonx.data. Each of these assets is documented in the catalogue with its schema, its access terms, its data classification, and its operational status.
The team submits an access request for all three assets through the fabric portal. The governance workflow routes the request to the owners of the Customer API — the customer management domain — the Order Event Topic — the order management domain — and the Inventory Data Source — the supply chain domain. Each owner reviews the request against the applicable governance policies: the customer management domain confirms that the digital retail channel’s purpose is consistent with the permitted uses of customer data; the order management domain confirms that event subscription is appropriate for the channel’s notification requirements; the supply chain domain confirms that inventory data access is within the approved scope. Access is granted, and the fabric automatically provisions the API subscription, the event topic subscription, and the data source access credential for the digital retail channel — a single governance process producing access across three integration disciplines simultaneously.
The digital retail channel team builds their integration flows in the European zone, where the customer data resides and where the channel’s primary user population is located. API Connect’s gateway in the European zone enforces the access policies for the Customer API, ensuring that each request from the digital retail channel carries the appropriate authorisation token and that the response is filtered to include only the customer attributes that the channel’s subscription authorises. IBM Event Streams in the European zone delivers Order Event notifications to the channel’s consumer application within milliseconds of the event’s publication, without the channel team needing to manage or operate any event streaming infrastructure. The Inventory Data Source, whose authoritative data resides in the Asian operational zone, is accessed through watsonx.data’s federated query interface: the query is executed in the Asian zone, and only the query result — the current stock level for the requested product — is returned to the European zone, with the cross-zone data transfer governed by the supply chain domain’s data sharing policy.
The fabric’s federated observability layer provides the digital retail channel team and the operations centre with a unified view of the integration’s operational health: API request latency and error rates from the European gateway, consumer lag metrics from the Event Streams broker, and query execution times from the watsonx.data federated query engine are all visible in the same operational dashboard, correlated by the transaction identifier that the fabric propagates through all integration interactions. When a performance issue arises — the inventory query response time increases due to increased load in the Asian zone — the operations team identifies and diagnoses the issue within the unified dashboard without needing to consult separate monitoring systems for the API, event, and data planes.
This worked example illustrates the practical value of the integration fabric model: the digital retail channel team accessed three different integration capabilities — API, event, and federated data — through a single governance process, within a single operational framework, without creating any unnecessary copies of customer, order, or inventory data. The Zero-Copy discipline was enforced not by the discipline of the individual development team but by the architecture of the fabric within which they built their integration.
9.7 The Integration Fabric and the Data Mesh
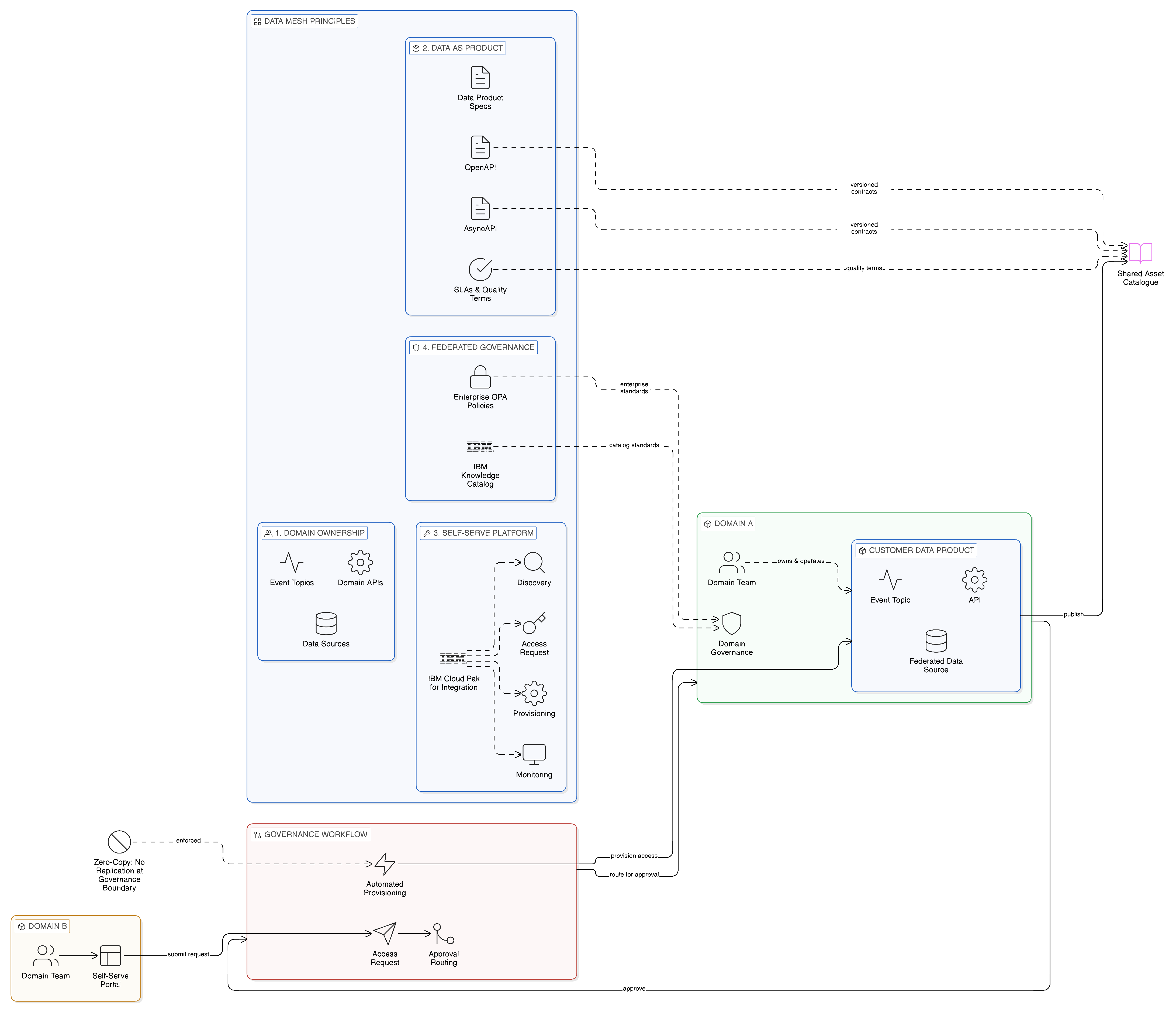
No contemporary discussion of enterprise integration architecture is complete without an examination of the data mesh, the organisational and architectural pattern proposed by Zhamak Dehghani that has attracted substantial attention from enterprise architects and technology leaders since its articulation in 2019. The data mesh is directly relevant to the integration fabric discussion because it addresses, from an organisational perspective, the same problem that the Zero-Copy philosophy addresses from a technical perspective: the failure of centralised, copy-centric data management to scale to the complexity of the modern enterprise.
The data mesh proposes four organising principles for enterprise data management: domain ownership of data, in which each business domain is responsible for the data that it generates and makes it available to other domains as a product; data as a product, in which domain data is designed, governed, and operated to the same quality standards as a software product, with defined schemas, SLAs, and access interfaces; a self-serve data platform, which provides the technical infrastructure that domains need to publish and consume data products without requiring specialised data engineering expertise; and federated computational governance, which establishes enterprise-wide data governance standards whilst allowing domains to implement those standards within their own data products.
The alignment between the data mesh principles and the Zero-Copy Integration philosophy is substantial, and deserves careful examination. Domain ownership of data is consistent with the Zero-Copy principle that data should remain in its authoritative location, owned and operated by the domain that generates it, rather than being extracted and centralised in a shared data store. The data mesh’s insistence that domains own their data and make it available through governed interfaces — rather than relinquishing it to a centralised data engineering team — is, in effect, an organisational expression of the same principle that drives the Zero-Copy architecture: data has a natural home, and moving it from that home creates costs, risks, and governance complexity that the organisation should seek to avoid. Data as a product is consistent with the contract-first design principle of the integration fabric, in which data sources are defined by published, versioned contracts that consuming teams rely upon rather than by informal data extracts arranged through direct team-to-team negotiation. The self-serve data platform is the technical implementation of the integration fabric’s shared catalogue and access provisioning capability. Federated computational governance is the organisational model that the integration fabric’s shared governance layer implements technically.
The integration fabric is, in effect, the technical implementation of the data mesh’s self-serve data platform principle: it provides the infrastructure through which domains can publish their data products — as APIs, event topics, and federated data sources — and through which consuming domains can discover and access those products without requiring direct coordination with the producing domain or the creation of centralised data copies. Adopting the integration fabric as described in this chapter and adopting the data mesh as an organisational operating model are therefore complementary rather than alternative strategies: the integration fabric provides the technology that makes the data mesh operationally feasible at enterprise scale. A data mesh without a capable integration fabric is an organisational model that cannot be implemented without recreating the point-to-point integration complexity and replication patterns that the mesh aspires to replace.
For the technology leader who is considering both the Zero-Copy Integration architecture and the data mesh operating model, the practical guidance is to treat the integration fabric as the technical foundation and the data mesh as the organisational model that governs how the fabric is used. The data mesh provides the domain ownership model that determines who publishes each integration asset to the fabric catalogue; the Zero-Copy philosophy provides the technical discipline that determines how data is made accessible through the fabric without replication; and the integration fabric provides the platform that enables both. These three frameworks are not competitors for the enterprise’s architectural attention; they are mutually reinforcing expressions of the same underlying insight about how complex organisations should manage data and integration in the multi-cloud era.
9.8 The Integration Fabric in the Enterprise Zero-Copy Architecture
The integration fabric, as described in this chapter, is the layer of the enterprise Zero-Copy architecture that unifies the Data, Application Integration, and Event planes described in preceding chapters into a single, coherent integration capability. It is not a separate architectural plane but a governance, management, and operational model that spans all three planes, providing the shared catalogue, unified access governance, federated observability, AI-assisted operations, and cost attribution capabilities that transform a collection of individually capable integration technologies into an enterprise integration platform.
For the CIO and CTO, the integration fabric represents a maturation of the enterprise’s integration capability from a project-by-project discipline to a platform-level strategic asset. Enterprises that manage integration at the project level — each project acquiring its own integration tools, establishing its own point-to-point connections, and operating its own monitoring infrastructure — will find that the cumulative cost of that fragmentation, in operational overhead, duplicated capability, inconsistent governance, and the replication-driven security and compliance exposure described throughout this book, exceeds by a substantial margin the investment required to establish and maintain a coherent integration fabric. The integration fabric is not a luxury for large enterprises but a necessity for any organisation whose integration estate has grown beyond the point at which it can be managed manually and consistently.
The relationship between the integration fabric and the Zero-Copy philosophy is, as this chapter has established, one of mutual reinforcement. The fabric makes Zero-Copy discipline operationally enforceable at scale, by providing the governance infrastructure through which data flow policies are defined and enforced across the full integration estate rather than applied inconsistently at the project level. The Zero-Copy philosophy makes the integration fabric more valuable than a conventional integration platform, by ensuring that the integration capabilities the fabric provides are designed to eliminate replication rather than to facilitate it, and that the cost, sovereignty, and security benefits of replication elimination accrue to the enterprise as a whole rather than remaining the concern of individual integration projects.
9.9 Summary and Architectural Imperatives
This chapter has examined the enterprise integration fabric as the unifying layer of the Zero-Copy Integration architecture: the governance, management, and operational model that transforms the individually capable integration planes described in preceding chapters into a coherent, governed, observable enterprise integration capability. The argument developed through the chapter may be summarised in five claims.
First, the integration fabric is defined not by the technical capabilities of its constituent components but by the shared governance, common catalogue, unified observability, and cost attribution that it provides across all integration disciplines. An enterprise that operates separate API management, event streaming, and data access platforms without a unifying governance and operational model has components but not a fabric; the fabric emerges from the management plane that unifies those components, not from the components themselves.
Second, the unification of API, Event, and Data integration within a single fabric governance model produces governance and operational benefits that no individual integration plane can deliver alone: a single integration discovery and access request experience for consuming teams; a unified operational view for the operations team; and a consistent, cross-plane enforcement of the data flow discipline that Zero-Copy Integration requires. Without this unification, the governance gaps between separately managed integration planes become the paths through which replication patterns re-emerge.
Third, IBM Cloud Pak for Integration provides the most comprehensive available implementation of the enterprise integration fabric concept on the OpenShift platform, and the open-source ecosystem — Apache Camel, Kong, Apache Kafka, Backstage — provides complementary capabilities that enrich the fabric in specific contexts. The technology leader’s strategic choice is not between commercial and open-source but between a deliberate, coherent fabric architecture that incorporates both and the unmanaged fragmentation that results from the absence of a unifying framework.
Fourth, AI-assisted integration operations — anomaly detection through IBM Instana, AI-assisted design through the Cloud Pak for Integration platform — are not future capabilities but present investments that address the fundamental scaling challenge of managing a large integration fabric: the ratio of integration complexity to the human capacity to govern it. Enterprises that defer these investments will find their governance quality degrading as their integration estates grow.
Fifth, the integration fabric and the data mesh are complementary strategies rather than alternatives: the integration fabric is the technical implementation of the data mesh’s self-serve data platform principle, and the two together provide a coherent organisational and technical framework for the sovereign, Zero-Copy enterprise.
Several architectural imperatives emerge from this analysis. The first is the establishment of a shared integration asset catalogue as the foundation of the fabric: without a catalogue, the integration estate remains opaque, duplication of integration capability continues unchecked, and consuming teams cannot discover the governed integration assets they need without creating shadow integration arrangements that undermine both governance and Zero-Copy discipline. The second is the design of the fabric’s governance model — its access policies, its cross-boundary rules, its cost attribution model — before the deployment of its execution infrastructure: governance policies that are added after the fact to an already-deployed integration estate are invariably incomplete and inconsistently applied, and remediation is substantially more costly than prevention. The third is the adoption of the distributed execution, federated observability topology described in the blueprint section of this chapter, ensuring that the integration fabric is itself designed with the sovereignty and resilience principles that it enforces for the integration assets it manages. The fourth is the deliberate evaluation of AI-assisted operations tooling — particularly IBM Instana’s anomaly detection and Cloud Pak for Integration’s AI design assistance — as a prerequisite for operating a large-scale integration fabric with acceptable governance quality and operational headcount.
The chapter that follows examines the network and topology dimension of the Zero-Copy enterprise architecture, addressing how the distributed execution topology of the integration fabric is shaped by the network fragility, latency characteristics, and sovereign zone constraints of the multi-cloud environment in which it operates.
If you are finding this content useful, please consider supporting the author's efforts by purchasing a complete digital or hard-copy version.
Zero-Copy Integration: Architecture for the Fragmented Enterprise
© 2026 by Alan Hamilton
is licensed under CC BY-SA 4.0
![]()
![]()
![]()