Chapter 13 — The Sovereign-by-Design Operating Model
Governance, Domain Ownership, and the Organisational Architecture of the Zero-Copy Enterprise
The preceding chapters of this book have been principally concerned with the technical architecture of Zero-Copy Integration: the Data Plane through which analytical and operational workloads access persistent assets without replication; the Application Integration and Event Planes through which services communicate and state changes propagate; the integration fabric that unifies these planes within a coherent governance and operational model; and the network, observability, continuity, and security disciplines that make the technical architecture resilient and sovereign by design. The argument has been that the technical disciplines of Zero-Copy Integration — query federation, event-driven communication, governed API contracts, and policy-enforced data flow control — can deliver the cost, sovereignty, and resilience benefits that the modern enterprise requires.
That argument, however, presupposes something that technical architecture alone cannot provide: an organisational model capable of sustaining the discipline that Zero-Copy Integration requires. The experience of enterprise architecture over several decades of digital transformation has repeatedly demonstrated that technically sound architectures fail when the organisational structures expected to implement and sustain them are misaligned with the principles those architectures embody. The centralised data lake fails not because federated query technology is unavailable but because the organisational incentives of individual business domains favour local data hoarding over the shared infrastructure investment that the lake requires. The integration fabric degrades into a collection of inconsistent point-to-point connections not because API governance technology is immature but because the teams responsible for individual integration flows lack the accountability structures that would make consistent governance a natural outcome of their work. The Zero-Copy discipline erodes into copy-centric integration not because replication-free access patterns are technically insufficient but because the short-term convenience of copying data is individually rational for each team even when it is collectively self-defeating for the enterprise.
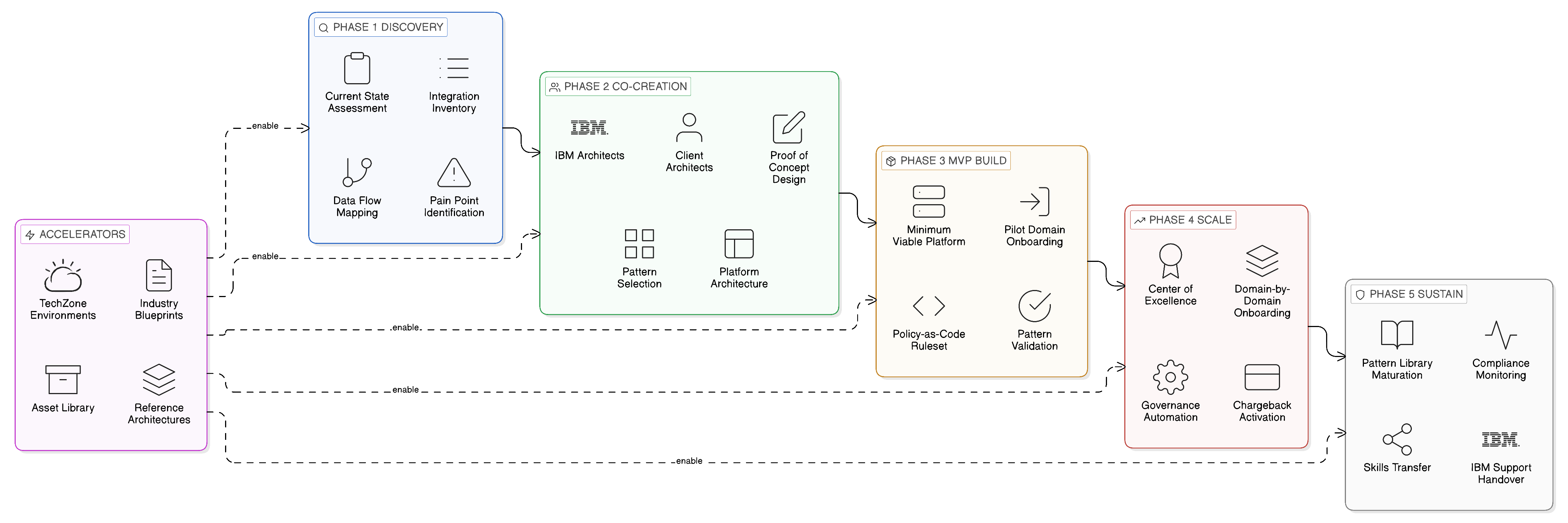
This chapter addresses the organisational architecture that the Zero-Copy enterprise requires. It examines the domain ownership model that distributes data accountability to the business units that generate and understand data, the three-platform model that provides the shared infrastructure through which domain teams exercise that accountability without acquiring specialised platform engineering expertise, and the governance model that maintains enterprise-wide policy coherence across a federated organisational structure. It examines the evolution of the CDO and CIO roles that the sovereign-by-design model demands, and the Centre of Excellence structure through which governance standards are developed and distributed across domain and platform teams. It addresses the practical disciplines of RACI definition, funding allocation, and chargeback design that determine whether Zero-Copy principles are sustained in practice or gradually abandoned under the commercial pressures of large-scale enterprise operation. It considers the role of the IBM Client Engineering methodology as an accelerator for the cultural and organisational transformation that the model requires. And it closes with the summary and organisational imperatives that translate the analysis into practical guidance for the technology leader.
13.1 The Failure of Centralised Control in a Federated World
The traditional enterprise approach to data and integration governance has been centralised: a central data team owns the data warehouse; a central integration team owns the middleware estate; a central IT organisation owns the infrastructure. This model has the apparent virtue of coherence — a single team accountable for each shared capability — and the practical virtue of simplicity in small organisations where the volume of data, integration flows, and consuming teams is modest enough to be managed by a central function.
At enterprise scale, however, centralised control creates a structural impediment to the sovereign, resilient architecture this book advocates. The central data team becomes a bottleneck through which all data access requests must pass, creating lead times measured in weeks for capabilities that the business requires in hours. The central integration team accumulates a growing estate of point-to-point connections that no individual within the team fully understands, making change expensive and risk assessment unreliable. The central IT organisation, responsible for maintaining the stability of a shared infrastructure on which all domains depend, develops a conservative disposition towards change that systematically disadvantages the agility that digital businesses require.
More fundamentally, centralised control is incompatible with the data sovereignty requirements that this book has identified as a defining constraint of the contemporary enterprise. A centralised data team that consolidates data from multiple jurisdictions into a shared repository necessarily creates the cross-border data flows and consolidated personal data assets that regulators such as the European Data Protection Board, the UK Information Commissioner’s Office, and their counterparts in other jurisdictions have placed under increasingly stringent controls. A centralised integration team that manages all data flows as shared infrastructure cannot provide the domain-specific access controls, jurisdiction-aware routing, and granular lineage tracking that compliance with data localisation requirements demands.
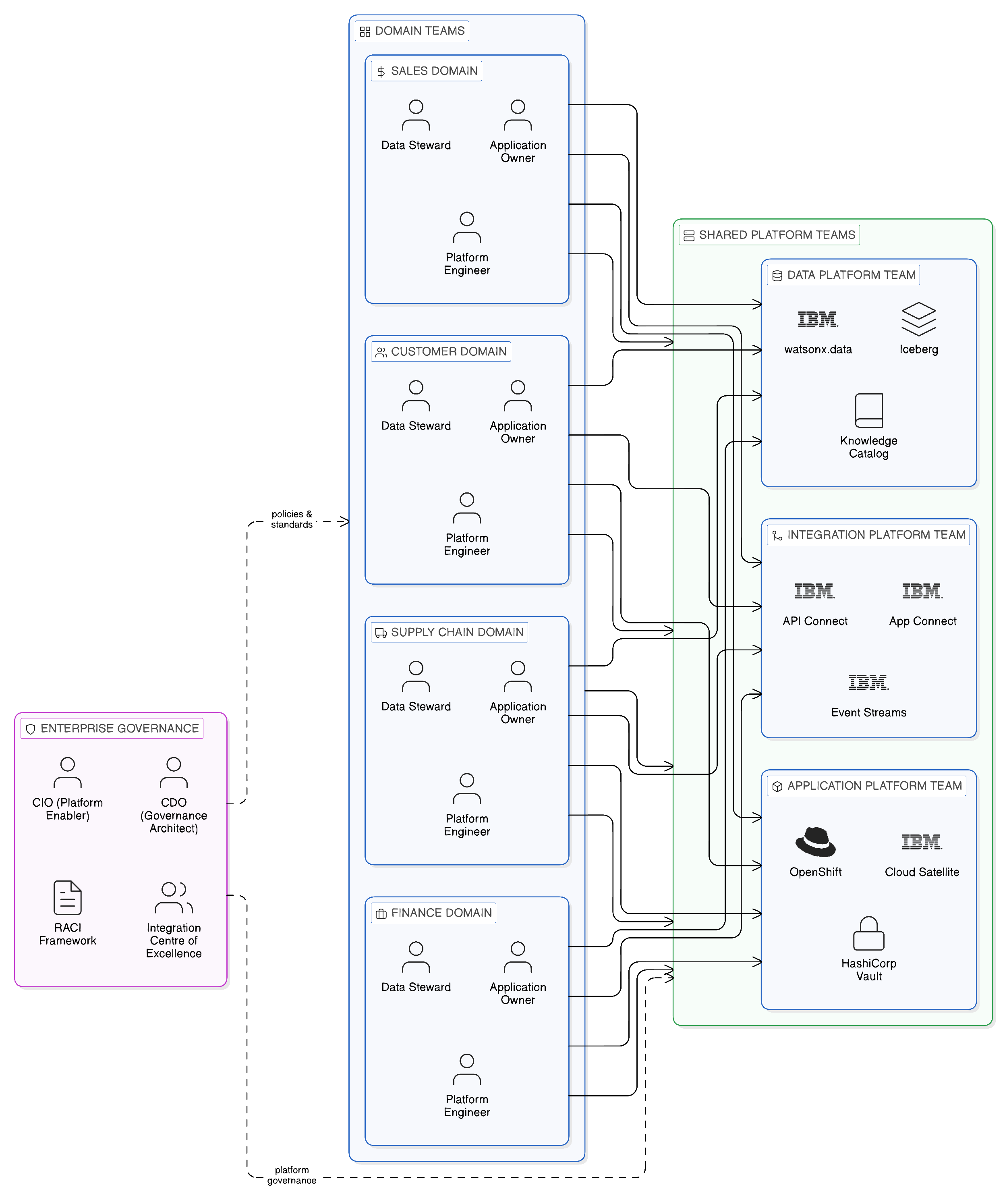
The sovereign-by-design operating model that this chapter describes begins from the recognition that data sovereignty and operational resilience are most reliably achieved not through centralised control but through distributed accountability, governed by enterprise-wide policy and supported by shared platform infrastructure. This is a subtle but important distinction. The enterprise does not abandon governance; it distributes the responsibility for implementing governance to the domain teams that are closest to the data and best positioned to understand the contextual requirements of data handling within their domain. The enterprise governance function shifts from ownership and operational control to policy definition, standards setting, and compliance assurance — a shift from doing to enabling, and from controlling to governing.
13.2 Domain Ownership: The Foundation of the Operating Model
The foundational principle of the sovereign-by-design operating model is domain ownership of data. Each business domain — understood as a cohesive set of business capabilities with a defined boundary and a stable organisational identity — owns the data that it generates and is responsible for making that data accessible to other domains through governed interfaces. The domain team designs, implements, operates, and governs its data interfaces; the enterprise governance function defines the standards to which those interfaces must conform.
This principle, articulated most systematically in Zhamak Dehghani’s Data Mesh framework and examined in Chapter 9 in its technical context, has direct and practical consequences for the Zero-Copy architecture. When domain ownership is genuinely implemented, the question “who is responsible for ensuring that this data is not replicated unnecessarily?” has a clear answer: the domain team that owns the data. When a consuming team requests access to domain data, the domain team designs an access mechanism — a federated query endpoint, an API contract, an event subscription — rather than providing a data extract. The consuming team’s incentive to request replicated data, which exists when replication is operationally easier than governed access, is countered by the domain team’s incentive to maintain a governed, auditable access model that satisfies the enterprise’s compliance requirements.
In practice, domain ownership requires clarity about domain boundaries that many enterprises find difficult to establish and maintain. The boundaries between domains are rarely as clear in practice as they appear in theoretical frameworks, and the political dimensions of data ownership — questions of which team controls which data, and therefore which team has the authority to restrict other teams’ access to it — can generate significant organisational friction. The experience of enterprise architects who have implemented domain ownership models consistently suggests that the most productive approach is to begin with the data assets about which ownership is clearest — transaction records, customer interaction logs, operational telemetry — and extend the model gradually to more contested data assets as the organisational patterns become established and the governance framework matures. The temptation to resolve domain boundary disputes through architectural fiat — assigning contested data to a central team to avoid the political difficulty of domain attribution — should be resisted, because it recreates the centralised ownership model that the federated approach is designed to supersede.
IBM’s approach to supporting domain ownership draws on both the integration fabric capabilities of IBM Cloud Pak for Integration and the data governance capabilities of IBM Knowledge Catalog. Within Knowledge Catalog, each data domain can be represented as a business glossary domain with defined stewards, published data assets, and documented access policies. The integration fabric’s shared catalogue provides the technical mechanism through which domain-published APIs, event topics, and federated data sources are discoverable and accessible to consuming teams. Together, these capabilities provide the technical infrastructure through which domain ownership is operationalised rather than remaining an organisational aspiration. The effectiveness of the technology, however, depends on the organisational discipline to use it consistently: a Knowledge Catalog that is sparsely populated because domain stewards are not held accountable for publishing to it provides no more governance assurance than a spreadsheet maintained on a shared drive.
13.3 The Three-Platform Model
The organisational structure that enables domain ownership at enterprise scale without sacrificing the coherence and reliability of shared infrastructure is the three-platform model: separate platform teams responsible for, respectively, the data platform, the integration platform, and the application platform. Each platform team provides the shared technical infrastructure and operational expertise that domain teams require to fulfil their data ownership responsibilities without acquiring and maintaining specialised platform engineering capabilities within each domain.
The data platform team is responsible for the infrastructure through which domain teams publish and govern their data assets: the federated query engine, the data catalogue, the policy enforcement layer, and the observability infrastructure through which data access patterns are monitored and audited. In an IBM environment, this team owns and operates IBM watsonx.data — the Presto-based federated analytics engine that enables in-place query across heterogeneous data sources — together with IBM Knowledge Catalog, IBM OpenPages for integrated risk and governance management, and the supporting infrastructure on Red Hat OpenShift. The data platform team does not own domain data; it provides the platform through which domain teams govern their own data in accordance with enterprise standards. It is the data platform team’s responsibility to ensure that the platform’s governance capabilities — the policy enforcement, access control, and lineage capture mechanisms — are configured correctly and operating reliably, and to provide the governance tooling through which domain stewards can manage their data assets without requiring specialised platform expertise.
The integration platform team is responsible for the shared integration fabric: the API gateway and management plane, the event streaming infrastructure, the message broker capability, and the unified integration catalogue through which integration assets are published and discovered. In an IBM environment, this team owns and operates IBM Cloud Pak for Integration, including IBM API Connect for API lifecycle management, IBM Event Streams for enterprise event streaming, IBM MQ for reliable transactional messaging, and the IBM App Connect integration runtime. The integration platform team does not own individual integration flows; it provides the platform through which domain teams implement and govern their own integration capabilities in accordance with the fabric’s governance standards. It is accountable for the availability and performance of the integration fabric, for the currency of the governance policies enforced by the gateway and broker infrastructure, and for the completeness of the integration catalogue through which consuming teams discover integration assets.
The application platform team is responsible for the container orchestration and application runtime infrastructure on which domain services, integration flows, and data products are deployed and operated. In an IBM environment, this team owns and operates Red Hat OpenShift, the enterprise Kubernetes platform that provides the compute substrate for the data and integration platforms as well as for domain application workloads. The application platform team does not own domain applications; it provides the runtime environment within which domain teams deploy and operate their own services in accordance with the enterprise’s operational standards. It is accountable for the availability, security, and operational performance of the OpenShift platform, and for the consistency of the platform’s configuration management, security policy, and network policy across all clusters in the enterprise’s sovereign topology.
The three-platform model is not a recommendation for organisational silos. Platform teams must collaborate closely and consistently — the integration fabric’s event streaming infrastructure must be designed to work within the application platform’s network policies; the data platform’s federated query engine must be deployed within the application platform’s resource management framework; the governance metadata maintained by the data platform team must be accessible to the integration platform’s catalogue — and this collaboration requires deliberate architectural coordination that should be formalised through a cross-platform architecture forum with regular cadence and shared ownership of the technical roadmap. What the model provides is clarity of accountability: each platform team has a defined scope of responsibility, and domain teams know which platform team to engage for which capability requirement. This clarity is essential for the operating model to function at enterprise scale, where the absence of clear accountability boundaries predictably produces both gaps in coverage and wasteful duplication.
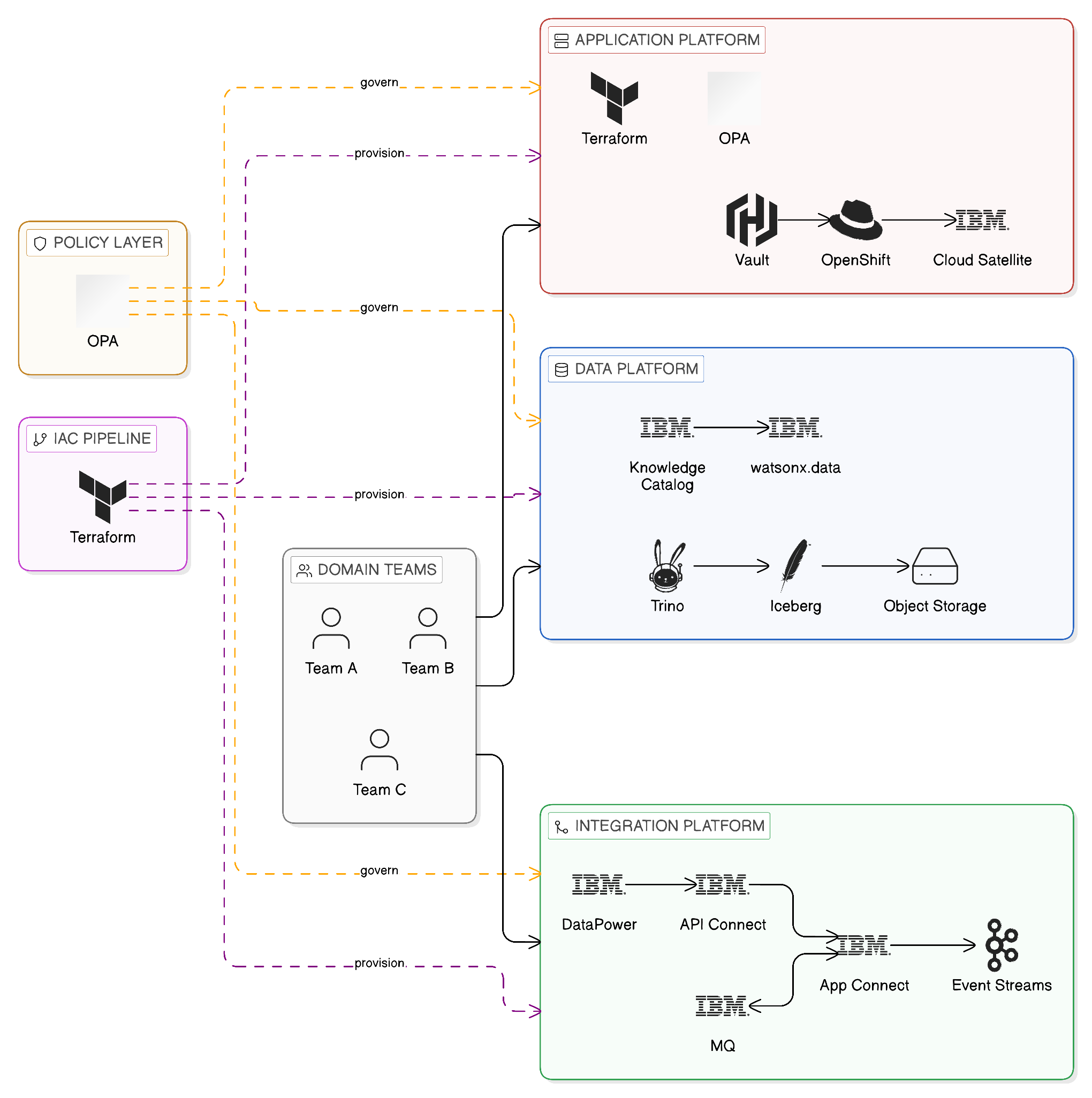
Two infrastructure disciplines — infrastructure provisioning and secrets management — underpin all three platform teams and require explicit organisational assignment within the three-platform model, because their scope spans the platform boundary and their absence from explicit governance accountability predictably produces the infrastructure-layer inconsistency that undermines platform-layer governance.
HashiCorp Terraform is the infrastructure provisioning discipline. The application platform team’s OpenShift clusters, the data platform team’s storage and compute resources, and the integration platform team’s network and load balancer configurations are all infrastructure artefacts that must be provisioned consistently and reproducibly across the enterprise’s sovereign zone topology. Terraform’s Infrastructure-as-Code model — declaring the desired state of infrastructure in version-controlled configuration files, with automated reconciliation ensuring that the running infrastructure matches the declared state — is the infrastructure-layer equivalent of the GitOps configuration management that governs application and integration component deployment. The application platform team typically owns the Terraform modules for OpenShift cluster provisioning; the cross-platform architecture forum is the governance mechanism through which the data and integration platform teams’ infrastructure requirements are expressed as parameters and constraints in those modules. Critically, the sovereign zone topology described in Chapter 10 must be reflected in the Terraform module design: each zone’s module must constrain provisioning to infrastructure within the applicable jurisdictional boundary, making it architecturally impossible to create infrastructure for a sovereign zone in a non-compliant location. Infrastructure that was hand-built rather than Terraform-provisioned is infrastructure whose sovereignty compliance cannot be verified from the configuration record — it must be re-provisioned under Terraform management before it can be considered part of the governed sovereign topology.
HashiCorp Vault is the secrets management discipline. The integration platform team’s API Connect consumer credentials, App Connect data source passwords, and Event Streams SASL authentication tokens; the data platform team’s watsonx.data connector credentials and Knowledge Catalog service credentials; and the application platform team’s cluster service account tokens and inter-service authentication certificates are all secrets whose lifecycle — creation, rotation, revocation, and audit — must be governed. Vault’s dynamic secrets model, in which short-lived credentials are generated on demand and automatically revoked at expiry, eliminates the credential proliferation that static secret distribution creates. Vault’s audit log, combined with IBM Guardium’s data access audit at the database layer, provides the complete credential and data access audit trail that regulatory compliance requires. The governance of Vault itself — which integration flows are authorised to request which credentials, and from which secrets engines — is expressed through Vault policies that are maintained as code in the same version-controlled repositories as the OPA and Kyverno policies described in Chapter 8, ensuring that the secrets management policy estate is under the same governance discipline as the data access and infrastructure policy estate. In practice, the Vault instance is owned by the application platform team as shared security infrastructure, with the data and integration platform teams defining their credential requirements as inputs to the Vault policy configuration that the application platform team maintains.
13.4 The Evolution of the CDO and CIO in the Sovereign-by-Design Model
The sovereign-by-design operating model does not merely adjust the responsibilities of existing roles; it requires a material evolution in the nature and focus of the Chief Data Officer and Chief Information Officer functions. Understanding this evolution is important for the technology leader who is navigating the organisational transformation that the model demands, because the roles that lead it must themselves embody the shift from centralised control to distributed governance that the model represents.
The Chief Data Officer’s role in the conventional enterprise has often been characterised by a tension between two mandates: the mandate to govern — to define and enforce the standards by which data is classified, handled, and protected — and the mandate to enable — to ensure that the business has access to the data it needs to operate and innovate. In a centralised data architecture, these mandates are structurally in conflict: the CDO who enforces strict governance is perceived by business units as a barrier to data access, whilst the CDO who prioritises access is perceived by the compliance function as insufficiently rigorous. The sovereign-by-design model resolves this tension by separating the governance mandate — which the CDO retains in the form of policy definition, standards setting, and compliance assurance — from the access enablement mandate, which is distributed to domain data stewards who are accountable for making their domain’s data accessible through governed interfaces. The CDO becomes the architect of the governance framework rather than the gatekeeper of data access, and the conflict between governance and enablement is resolved by distributing enablement to the domain while retaining policy authority at the enterprise level.
In this evolved model, the CDO’s primary outputs are the enterprise data governance policies — the data classification framework, the cross-border data flow rules, the access control standards, the retention and deletion schedules — that domain stewards implement within their domains. The CDO function also owns the enterprise’s relationship with data regulators, the response to data subject access requests that span multiple domains, and the oversight of the domain stewards’ governance performance through the metrics and audit evidence generated by IBM Knowledge Catalog and IBM Guardium. The CDO does not manage individual data assets; the domain stewards do. The CDO manages the framework within which all domain stewards operate.
The Chief Information Officer’s role evolves in a complementary direction. The CIO in the sovereign-by-design model is the owner of the three-platform model: the executive accountable for the availability, capability, and strategic direction of the data platform, integration platform, and application platform teams. The CIO’s primary strategic question is no longer “which systems should we build or buy?” but “how do we provide the platform infrastructure that enables domain teams to build and govern their own capabilities within the enterprise’s sovereignty and resilience framework?” This is a fundamentally different kind of technology leadership: less focused on individual system delivery and more focused on platform capability, governance architecture, and the organisational model that makes the platform productive for its domain team consumers.
The CIO is also the executive accountable for the enterprise’s operational resilience posture, as described in Chapter 12: the adequacy of the BC/DR architecture, the currency of recovery runbooks, the results of chaos engineering exercises, and the evidence presented to regulators in the context of DORA and comparable frameworks. In the distributed topology of the Zero-Copy architecture, the CIO’s resilience accountability is mediated through the three platform teams and the sovereign zone topology, rather than through a single centralised infrastructure team. This distributed accountability model is more complex to manage but more robust in its resilience outcomes.
13.5 The Integration Centre of Excellence
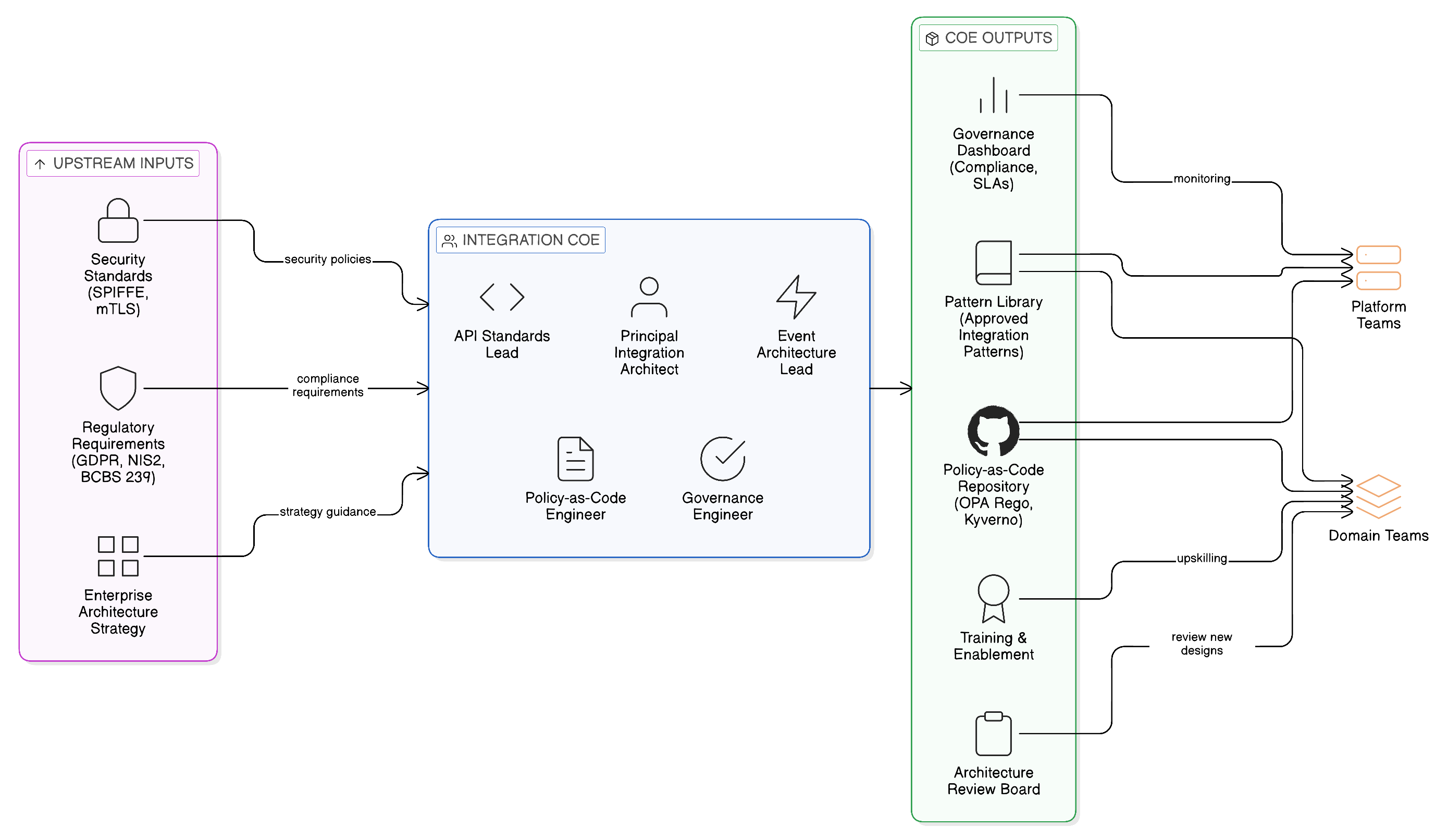
The three-platform model provides the structural framework for shared platform infrastructure, but it does not in itself provide the mechanism through which governance standards are developed, communicated, and embedded in the day-to-day practice of domain and platform teams. This is the function of the Integration Centre of Excellence: the cross-cutting capability that translates enterprise governance policy into actionable architectural standards, reference implementations, and enabling tooling that domain teams can use without requiring specialist governance expertise in each domain.
The Integration Centre of Excellence is not a fourth platform team, and it does not have operational responsibility for any integration infrastructure. Its role is architectural and enabling: it defines the integration patterns that conform to the enterprise’s sovereignty and resilience requirements, produces the reference implementations and code templates that make those patterns easy to adopt, maintains the governance policy library that is deployed through OPA and Kyverno as described in Chapter 8, and provides the architectural review capability that validates new integration designs before they enter production. The Centre of Excellence is staffed by a small number of senior integration architects — typically four to eight individuals in a large enterprise — who have deep expertise in Zero-Copy Integration patterns, the IBM and open-source platform capabilities that implement them, and the regulatory frameworks that govern data handling in the enterprise’s operating jurisdictions.
The practical mechanism through which the Centre of Excellence influences domain and platform team behaviour is the integration pattern library: the documented catalogue of approved integration patterns, each specified at the level of detail required for a domain team to implement it correctly. An entry in the pattern library for the event-driven data access pattern, for example, specifies not merely the high-level design — consumer subscribes to a topic, processes events, accesses data in place — but the specific Kafka topic configuration standards, the OPA policy template for consumer authorisation, the OpenTelemetry instrumentation requirements, the IBM Knowledge Catalog registration steps, and the Zero-Copy governance checklist that must be completed before the pattern is considered production-ready. This level of specificity is essential: a pattern library that specifies designs at too high a level produces inconsistent implementations; one that specifies them at the implementation level enables consistent, repeatable adoption across domain teams of varying maturity.
The Centre of Excellence also maintains the enterprise’s policy-as-code estate: the OPA policy bundles that enforce data classification controls, cross-boundary routing rules, and access authorisation standards at the infrastructure level, and the Kyverno admission policies that prevent the deployment of integration components that do not conform to the enterprise’s security and governance standards to the OpenShift platform. The maintenance of this policy estate is not merely a technical activity; it requires ongoing dialogue between the Centre of Excellence architects, the CDO’s governance team, and the legal and compliance function to ensure that the implemented policies accurately reflect the regulatory obligations applicable in each sovereign zone. Policy changes that result from regulatory updates — a new data localisation requirement in a specific jurisdiction, a change in the GDPR guidance on international data transfers — must be translated into updated OPA policies, tested against the existing integration estate to identify affected flows, and deployed through the GitOps configuration management process before the regulatory deadline.
The Centre of Excellence’s engagement model with domain teams is consultative rather than directive in normal operations: domain teams engage the Centre of Excellence when they are designing new integration capabilities, when they are uncertain about the governance requirements for a particular data type or integration pattern, or when they are preparing for the governance review that precedes production deployment. The Centre of Excellence provides the expertise and the tooling; the domain team retains accountability for the governance of its own integration flows. This model scales in a way that a directive, approval-based governance model cannot: the Centre of Excellence’s capacity is not a bottleneck for domain team delivery, because domain teams do not require its approval for every integration decision — only for the subset that presents novel governance questions or that falls outside the approved pattern library.
13.6 RACI for the Zero-Copy Enterprise
The domain ownership and three-platform model establish the structural foundation of the operating model, but structure alone does not determine behaviour. The Responsibility, Accountability, Consultation, and Information (RACI) matrix for the key governance decisions of the Zero-Copy enterprise must be explicitly defined and consistently applied if the operating model is to produce the sovereignty and resilience outcomes it promises.
For data interface design — the decision about how a domain’s data assets are made accessible to consuming teams — accountability rests with the domain data steward: the individual within the domain who is responsible for the data governance of the domain’s data assets. Responsibility for the technical implementation of the interface is shared between the domain’s engineering team and the data platform team, who provide the federated query infrastructure and the catalogue registration mechanism. The Centre of Excellence is consulted to ensure that the interface design conforms to the approved pattern library and that the governance checklist is completed. The enterprise governance function is consulted to confirm that the access controls satisfy the applicable data classification requirements. Consuming teams that will use the interface are informed of its design, its access terms, and its SLA before publication.
For integration flow design — the decision about which integration pattern, protocol, and data format will be used for a specific integration between two domain services — accountability rests with the integration architect for the domain that originates the integration. Responsibility for governance compliance is shared between the originating domain and the integration platform team, who validate that the proposed flow satisfies the fabric’s sovereignty routing policies and the Centre of Excellence’s pattern standards. The compliance function is consulted when the integration involves personal data, regulated content, or cross-boundary data flows that require legal basis assessment. Consuming domains are informed of the integration contract and its governance classification before it enters production.
For policy definition — the enterprise-wide policies that govern data classification, cross-border data flows, access control standards, and audit logging requirements — accountability rests with the Chief Data Officer, advised by the legal and compliance function. The Centre of Excellence is consulted in the development of policies to ensure that they are technically implementable within the platforms’ governance infrastructure and expressible in the OPA policy language used for automated enforcement. Platform teams are consulted to assess the operational implications of proposed policy changes. Domain teams are informed of policy changes with appropriate notice periods — at minimum four weeks for changes that require modification of existing integration flows — that allow them to adapt their implementations accordingly.
For sovereignty and resilience incidents — situations in which a data access pattern has violated a sovereignty policy, an integration flow has created an unexpected cross-border data transfer, or a resilience mechanism has failed — accountability for the business impact rests with the domain that owns the data asset involved. The platform team responsible for the infrastructure through which the incident occurred is responsible for providing the technical root cause analysis. The Centre of Excellence is consulted on remediation options and on whether the incident reveals a gap in the pattern library or the policy estate that requires a systemic response. The enterprise governance function is informed of all sovereignty incidents and is consulted on remediation plans before they are implemented; for incidents that may have regulatory notification obligations, the CDO is immediately informed and the legal function is engaged.
13.7 Funding Models and Chargeback for Federated Services
One of the persistent practical challenges of the federated operating model is the funding of shared platform infrastructure. Platform teams provide services that are consumed by all domain teams, but their costs are not directly attributable to individual consuming teams in the straightforward way that project-specific infrastructure costs can be attributed. The result, in many enterprises, is that platform teams are funded through a central IT budget that is not easily adjusted to reflect the actual consumption patterns of domain teams, creating perverse incentives: domain teams consume shared infrastructure without bearing the cost of overconsumption, whilst platform teams are pressured to reduce costs without reference to the service levels that domain teams require.
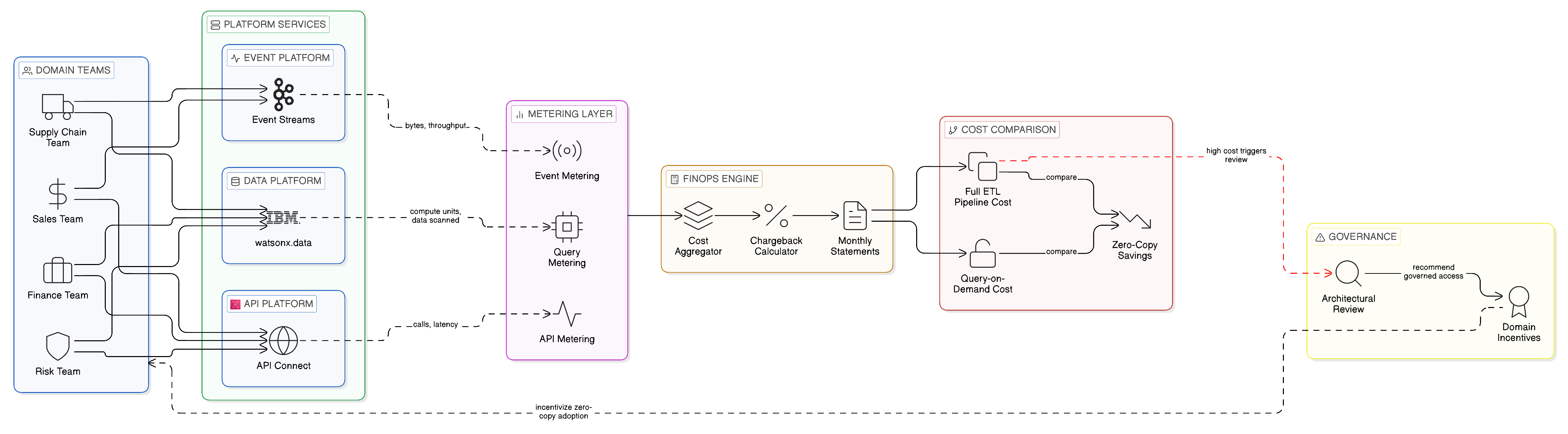
The sovereign-by-design operating model requires a funding model that aligns the economic incentives of domain teams with the Zero-Copy discipline that the operating model is designed to sustain. The most effective approach is a consumption-based chargeback model in which platform teams recover their costs from domain teams based on measured consumption of platform services: the volume of API transactions handled by the integration platform, the volume of event messages processed by the event streaming infrastructure, the volume of federated query compute consumed by the data platform. Consuming domain teams pay for what they consume; originating domain teams are charged for the cost of operating the interfaces through which their data is accessed.
This consumption-based model creates direct economic incentives for the Zero-Copy discipline. When domain teams pay for egress and replication as well as for governed access, the economic case for Zero-Copy Integration becomes visible at the domain level rather than remaining an enterprise-wide concern that is opaque to individual teams. The team that consumes data through a federated query endpoint pays for the compute cost of query execution but avoids the storage, network egress, and operational costs of maintaining a replicated data asset. The team that subscribes to an event topic pays for the event processing cost but avoids the overhead of polling mechanisms or batch data transfers. The team that creates an unnecessary data copy faces a charge for the egress, storage, and governance overhead of that copy — a concrete economic consequence that makes the architectural argument tangible and self-reinforcing. The economic model reinforces the architectural model in a way that governance policies enforced by technology alone cannot.
IBM’s FinOps capabilities within watsonx.data and Cloud Pak for Integration provide the cost attribution and consumption measurement infrastructure that the chargeback model requires. Query execution costs within watsonx.data can be attributed to the consuming team’s identity through the platform’s workload identity integration. API transaction volumes within IBM API Connect are measured and reportable per consumer application and per plan tier, enabling fine-grained attribution of integration consumption to the domain teams and business processes that drive it. IBM Instana’s infrastructure utilisation telemetry, described in Chapter 11, provides the resource-level consumption data that underpins the platform teams’ cost recovery models and enables the FinOps practitioners who administer the chargeback to identify and investigate consumption anomalies. Together, these capabilities provide the technical foundation for a chargeback model that makes the economic benefits of Zero-Copy Integration visible and measurable at the domain level.
The design of the chargeback model must, however, avoid the perverse consequences that poorly designed chargeback mechanisms can produce. A chargeback model that makes governed access prohibitively expensive relative to the cost of building a private integration will drive domain teams towards exactly the shadow integration patterns that the governed fabric exists to prevent. The chargeback should recover the real costs of the platform service — including the governance overhead that makes the service compliant and auditable — but should be calibrated so that governed access remains materially cheaper than the total cost of ownership of a privately built alternative. The governance overhead that the platform absorbs — the cost of maintaining the pattern library, the policy estate, the lineage capture infrastructure, the compliance reporting — is a genuine cost reduction relative to the alternative of each domain team maintaining its own governance capability, and this should be reflected in the comparative economics presented to domain owners when the chargeback model is introduced.
13.8 IBM Client Engineering as an Operating Model Accelerator
The transition from a centralised, copy-centric operating model to the distributed, domain-owned, Zero-Copy operating model described in this chapter is a significant organisational change that cannot be achieved through architectural decree alone. It requires the development of new working practices, new collaborative patterns between domain teams and platform teams, and new governance habits that become embedded in the day-to-day work of engineering and data teams. This kind of cultural and operational transformation is notoriously difficult to accelerate, and the history of enterprise architecture is littered with reference architectures that were technically sound but organisationally stranded because the transformation programme that was expected to implement them lacked the methodology to translate architectural principle into operational practice.
IBM’s Client Engineering approach offers a structured approach to this transformation challenge that has been applied in enterprise data and integration transformation programmes across multiple industries. The Client Engineering model is built on the principle of co-creation: IBM architects, data engineers, and transformation practitioners work alongside the client’s domain teams and platform teams within a structured programme of capability building that delivers working capabilities — implemented data interfaces, governed integration flows, operational observability dashboards — whilst simultaneously transferring the skills and knowledge that the client’s teams need to sustain and extend those capabilities independently. The methodology is explicitly designed to leave the client more capable than it was before the engagement, not merely to deliver technical artefacts that the client cannot maintain without continued external dependency.
Within the context of the Zero-Copy operating model, the Client Engineering approach provides a practical path from the aspirational to the operational. A typical engagement begins with an architectural assessment that establishes the current state of the enterprise’s integration estate and data governance posture, maps the sovereign zone requirements applicable to the enterprise’s operating jurisdictions, identifies the highest-value opportunities for Zero-Copy transformation, and defines the target operating model in terms of the domain boundaries, platform team responsibilities, Centre of Excellence structure, and governance processes that will govern the transformed state. This assessment is not a theoretical document; it is a working engagement that involves domain architects, data stewards, compliance representatives, and platform engineers alongside the IBM practitioners, because the operating model must reflect the actual organisational reality of the enterprise rather than a generic template.
The assessment is followed by a focused build programme in which a small, multi-disciplinary team — IBM practitioners working alongside the client’s domain architects, data stewards, and platform engineers — implements the first instances of the target operating model: the first domain data interfaces published to the integration fabric catalogue, the first federated query endpoints registered in IBM Knowledge Catalog, the first event-driven integration flows deployed through the Cloud Pak for Integration runtime, and the first OPA governance policies deployed through the Centre of Excellence’s policy-as-code pipeline. These first implementations serve two simultaneous purposes: they deliver genuine business value — the first governed access to a previously replicated dataset eliminates a data extract pipeline and its associated cost and sovereign risk — and they establish the reference patterns that subsequent domain implementations will follow.
The value of this co-creation approach lies not only in the working capabilities it delivers but in the patterns, habits, and institutional knowledge it establishes within the client’s teams. The first implementation of a domain data interface, done correctly within the Client Engineering programme, becomes the reference against which subsequent implementations are measured; the domain architects who built it become internal advocates for the pattern, spreading both the technical knowledge and the organisational confidence that the approach works. The first experience of the consumption-based chargeback model, made real through actual cost attribution within the FinOps dashboard, creates the economic reality that makes subsequent adherence to Zero-Copy discipline self-reinforcing. The first compliance audit conducted against the lineage metadata published to IBM Knowledge Catalog demonstrates to the compliance function that the sovereignty posture of the federated operating model is auditable and defensible — in ways that the centralised, copy-centric model never was — providing the compliance team’s endorsement that accelerates adoption across the remaining domain teams.
Measuring the effectiveness of the operating model transformation requires metrics that go beyond the technical — the number of APIs published, the volume of events processed — to capture the organisational and governance outcomes that the model is designed to produce. The proportion of data access by domain teams that flows through governed interfaces rather than direct database connections or data extracts is the most direct indicator of Zero-Copy discipline adoption. The time from a consuming team’s access request to provisioned access is the service quality indicator for the integration fabric catalogue and the access governance workflow. The completeness of lineage coverage in Knowledge Catalog — the proportion of data assets and integration flows for which lineage metadata is current and accurate — is the indicator of governance maturity. And the ratio of governance incidents — sovereignty violations, policy breaches, ungoverned data flows identified by Guardium — to the total volume of integration activity is the compliance quality indicator that demonstrates, to both internal governance functions and external regulators, that the sovereign-by-design model is producing the outcomes it promises.
13.9 Summary and Organisational Imperatives
The sovereign-by-design operating model is not an organisational aspiration that depends upon technical architecture for its realisation; it is the organisational precondition for technical architecture to be sustained. The Zero-Copy Integration principles that this book has advocated are technically implementable with current platform capabilities — IBM watsonx.data, IBM Cloud Pak for Integration, IBM Knowledge Catalog, Red Hat OpenShift, and the open-source ecosystem that complements them provide the technical foundation. What those platforms cannot provide is the organisational discipline to operate within the governance framework they enable. That discipline requires domain ownership, platform teams, a Centre of Excellence, explicit RACI definitions, evolved CDO and CIO roles, economic incentive alignment, and a transformation methodology capable of making the model operational. The argument developed through this chapter may be summarised in five claims.
First, centralised data and integration governance is structurally incompatible with the sovereignty, resilience, and agility requirements of the contemporary enterprise at scale. The sovereign-by-design model resolves this incompatibility by distributing accountability for data governance to the domain teams that own the data, governing that distributed accountability through enterprise-wide policies, and providing the shared platform infrastructure that makes governed access operationally easier than ungoverned replication.
Second, the three-platform model — separate data platform, integration platform, and application platform teams — provides the shared infrastructure foundation that enables domain ownership at enterprise scale. The clarity of accountability that the model provides, combined with the collaborative architecture coordination that prevents it from fragmenting into silos, is the organisational mechanism through which the Zero-Copy architecture’s technical capabilities are made available to all domain teams without requiring each domain to acquire and maintain specialist platform expertise.
Third, the CDO and CIO roles must evolve materially in the sovereign-by-design model: the CDO from gatekeeper to governance architect, responsible for the policy framework that domain stewards implement rather than for the data assets themselves; the CIO from system deliverer to platform enabler, responsible for the shared infrastructure capability and the organisational model that makes it productive. These are not incremental adjustments to existing roles; they represent a substantive shift in focus and authority that must be explicitly recognised and managed in the organisational change programme.
Fourth, the Integration Centre of Excellence is the mechanism through which governance standards are translated into actionable patterns, implemented as policy-as-code, and distributed to domain and platform teams in a form that enables consistent adoption without creating a governance bottleneck. Without the Centre of Excellence, the distance between enterprise policy and domain implementation practice will grow as the integration estate scales, producing the governance inconsistencies that erode sovereignty posture and expose the enterprise to compliance risk.
Fifth, the funding and chargeback model is an architectural governance instrument, not merely an accounting mechanism. A chargeback model that makes the economic consequences of replication visible to domain teams at the point of their integration design decisions is more effective at sustaining Zero-Copy discipline than any volume of governance documentation or architectural review, because it aligns the individual rational interest of each domain team with the collective architectural interest of the enterprise.
Several organisational imperatives emerge from this analysis. The first is the explicit definition of domain boundaries and the assignment of data ownership accountability, with named domain data stewards, before the technical infrastructure of the Zero-Copy architecture is deployed. A shared catalogue to which no team has been assigned as a publishing owner, a governance policy to which no team has been assigned as the accountable implementer, will not produce the disciplined behaviour that the Zero-Copy model requires. The second is the establishment of platform teams with clear mandates and sustained funding, insulated from the project-level budget pressures that cause shared platform infrastructure to be undermined in favour of project-specific solutions; sustained platform investment is not a cost to be minimised but the enabling condition for the domain team productivity and governance consistency that the model depends upon. The third is the establishment of the Integration Centre of Excellence with the senior architectural expertise and governance mandate required to maintain the pattern library and policy-as-code estate at the quality the enterprise’s regulatory obligations demand; the Centre of Excellence must be funded as a permanent governance capability, not as a time-limited project team. The fourth is the design of the funding and chargeback model as a deliberate instrument of architectural incentive alignment before it is introduced, ensuring that the comparative economics favour governed access and that the model’s introduction is accompanied by the communication and education that makes its rationale transparent to domain teams and their business leaders.
The chapter that follows examines the skills, talent, and cultural dimensions of the transformation, addressing the specific capabilities that architects, data engineers, and domain teams must develop to operate effectively within the sovereign-by-design model.
If you are finding this content useful, please consider supporting the author's efforts by purchasing a complete digital or hard-copy version.
Zero-Copy Integration: Architecture for the Fragmented Enterprise
© 2026 by Alan Hamilton
is licensed under CC BY-SA 4.0
![]()
![]()
![]()